Auto-tuning Interactive Ray Tracing using an Analytical GPU Architecture Model
GPGPU-5, the 5th Annual Workshop on General Purpose Processing with Graphics Processing Units, London UK, March 2012.
Abstract
This paper presents a method for auto-tuning interactive ray tracing on GPUs using a hardware model. Getting full performance from modern GPUs is a challenging task. Workloads which require a guaranteed performance over several runs must select parameters for the worst performance of all runs. Our method uses an analytical GPU performance model to predict the current frame’s render- ing time using a selected set of parameters. These parameters are then optimised for a selected frame rate performance on the particular GPU architecture. We use auto-tuning to determine parameters such as phong shading, shadow rays and the number of ambient occlusion rays. We sample a priori information about the current rendering load to estimate the frame workload. A GPU model is run iteratively using this information to tune rendering parameters for a target frame rate. We use the OpenCL API allowing tuning across different GPU architectures. Our auto-tuning enables the rendering of each frame to execute in a predicted time, so a target frame rate can be achieved even with widely varying scene complexities. Using this method we can select optimal parameters for the current execution taking into account the current viewpoint and scene, achieving performance improvements over predetermined parameters.
Downloads
Author generated version of the paper
Ivy Bridge Intel HD 4000 GPU addendum
10th October 2012
Sometime after this paper was presented, the Intel Ivy Bridge generation of processors was introduced. These processors had Intel's first DirectX 11 and OpenCL 1.1 capable GPU. We ported the GPU model and auto-tuned ray tracer to a 3.4 GHz Core i5-3570K and generated the following results. The two notable results are the sheer performance of the GPU compared to the discrete GPUs at this particular task. For example, the HD4000 actually traces slightly more AO rays for the fairy scene than the Radeon 5870 (from 2009) at the same performance. Also the state of the OpenCL compiler for the HD4000 made getting the kernel to work challenging.GPU parameters
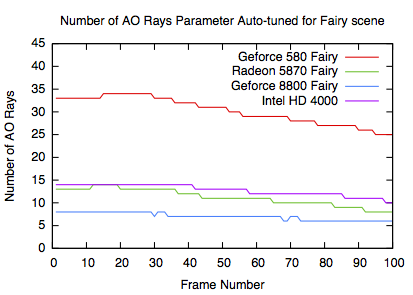
The GPU parameters for the Intel HD 4000 are not clearly defined in documentation like other GPUs. The benchmarking application and simulated annealing were used over most GPU parameters to get the best fit. This resulted in the somewhat unrealistic variables below, but ultimately they are the variables that best tune the model to the benchmarked results. Instead of maximum blocks per core, maximum warps per multiprocessor was benchmarked at 350. Also the number of coalesced and uncoalesced memory transactions per warp were estimated at 27 and 1 respectively.
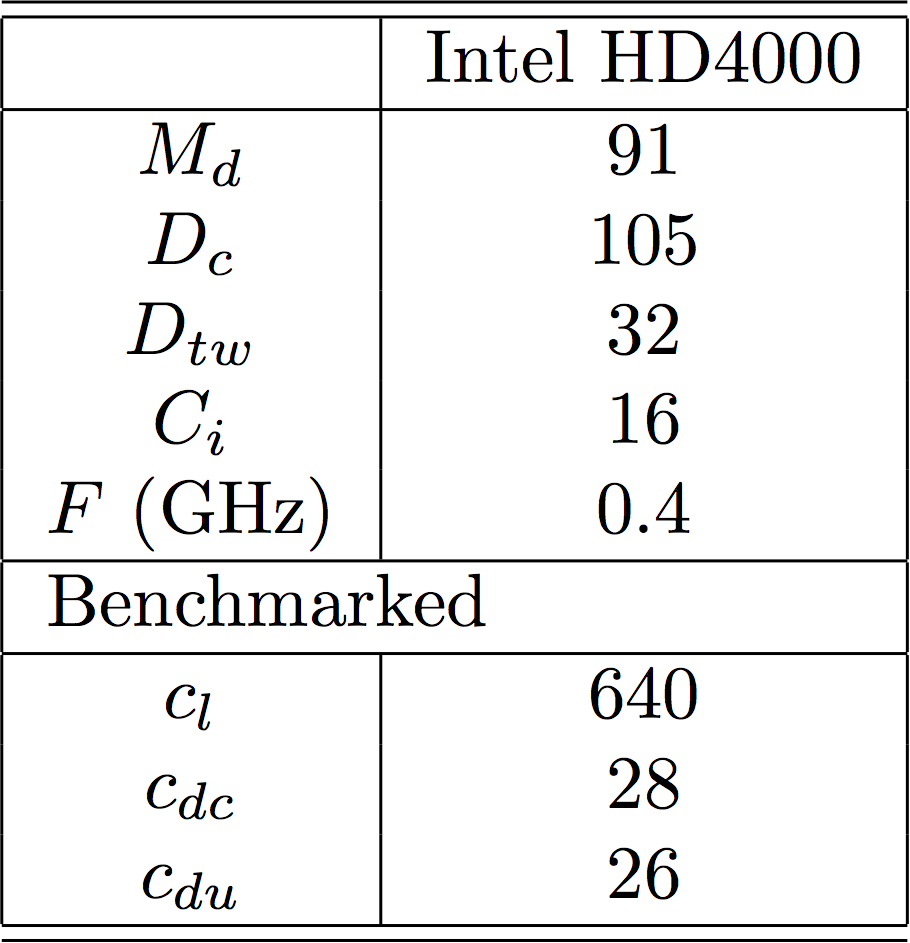
Frame times
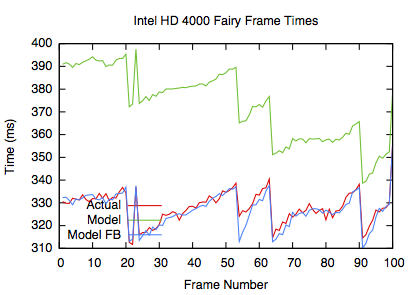
The frame times show that the model can very actually track the applications frame to frame behaviour, but there is an offset where the overall performance of the GPU isn't correctly measured leading to the offset error seen in the graphs. The performance targets for the Fairy and Cabin are 333ms and 600ms respectively.
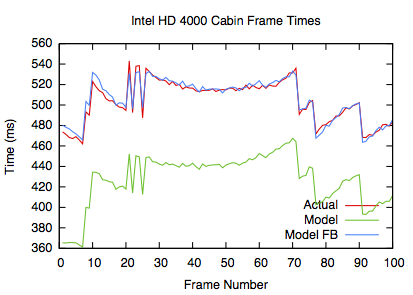
Auto-tuned Ambient Occlusion rays
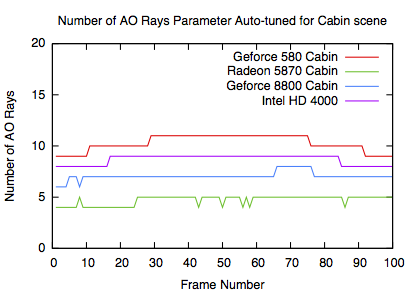
Here the HD4000 shows a similar behaviour as the other GPUs. Again it's noticable that the HD4000 has slightly more AO rays than the 5870, while running at roughly the same speed. Generally though the number of AO rays between GPUs cannot be compared in these graphs because each GPU has different frame time targets.
Model errors
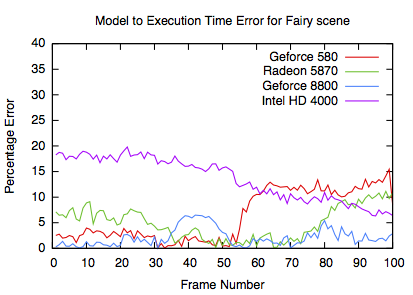
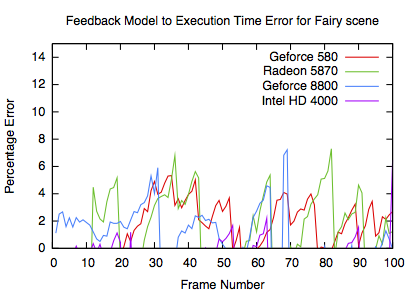
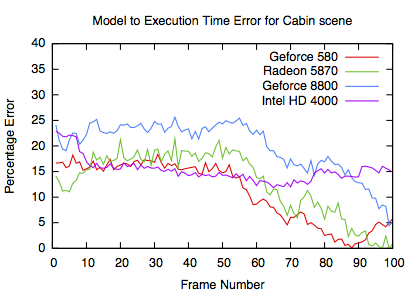
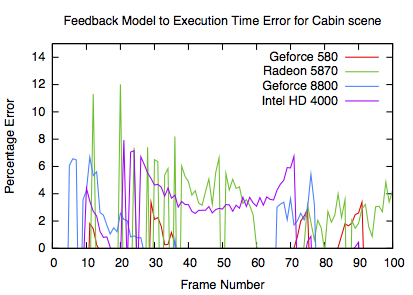
The errors are similar to the other GPUs. It is notable that the HD4000 has a more consistent error, most likely due to the lack of good GPU parameters.