Lecture 5 – notes
This is a short description of what we did during lecture 5. I spent most of the time going through examples which I hope can be of help to you when you're about to solve lab 3 and the project – the slides are here.
Event sourcing
First we discussed ways to implement bank accounts – one simple way is to just keep the state of an account in a mutable attribute:
class Account {
private int accountNumber;
private double balance;
public void deposit(double amount) {
balance += amount;
}
public double withdraw(double amount) {
var actual_amount = Math.min(amount, balance);
balance -= actual_amount;
return actual_amount;
}
public double balance() {
return balance;
}
}
This is conceptually very simple, but there are some drawbacks:
- We know the balance of the account, but we don't know why it is the way it is.
- To update the account, we need to make sure that no one else updates it at the same time, so we need to use some kind of lock.
Because of this, it's become commonplace to save state updates instead of the state itself – in the case of bank accounts we would save all transfers, and then calculate the balance by going through all transfers (we could also 'cache' the balance at some point in time, and then just look at transfers after it). This is called event sourcing, and it gives us the account's history, and allows us to explain why we have the current balance. It also makes it 'cheaper' to alter the state of the accounts, we only need to add new transfers (we'll talk more about this in a few weeks time).
In lab 2 you'll need to think about how to keep track of the number of available seats for a performance – there are several ways, one of them is using event sourcing.
About DBMS's and SQLite
We then looked a drawing illustrating how we can use a database server:
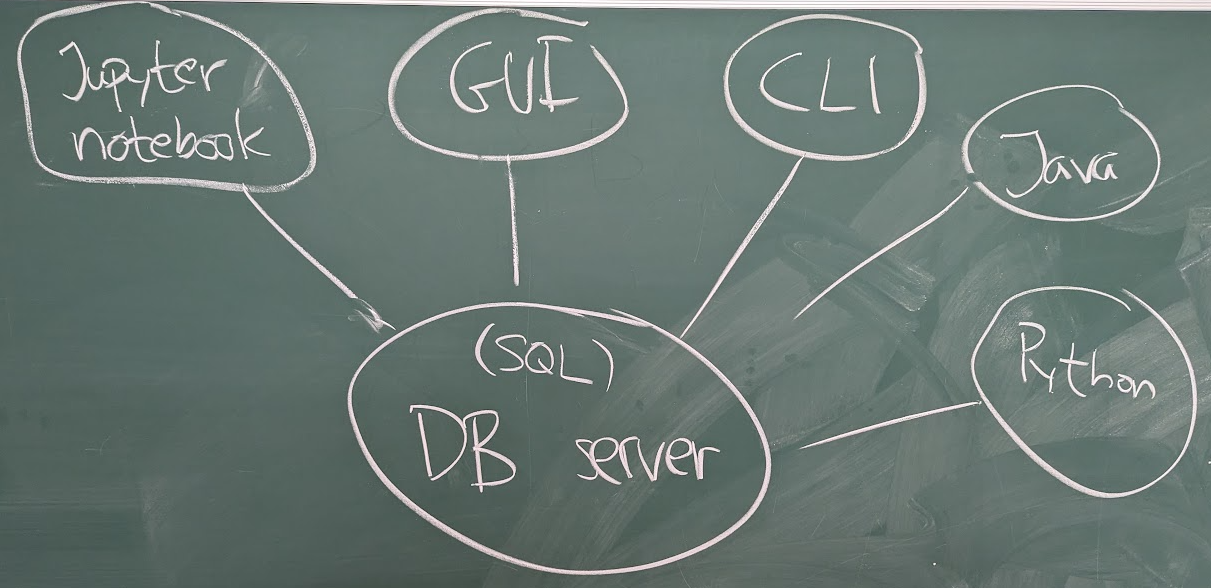
I said that a DBMS normally runs as a server, and we talked about different ways of communicating with our database server:
- Using a notebook, such as the Jupyter notebooks we've used for lectures and lab 1.
- Using some kind of dedicated graphical client (a GUI), such as sqlitebrowser – I showed it to you briefly.
- Using a command line SQL-client, such as
psqlfor PostgreSQL, orsqlite3for SQLite (SQLite doesn't really run as a server, but when we run the command line client, it looks like it). - Using a program written in a traditional language, such as Java, or Python.
- Using some kind of microservice (typically REST) – this is just an example of the previous category, but it's very common, and they're typically used as backends for various web frontends – we'll return to this on Thursday (and on lab 3 and the project).
Using SQLite from a command line client
After the lecture I got some questions about what programs I was using, and it made me realize that some of you are not used to working with a command line interpreter (CLI) – I'd be happy to show you, and answer any question about it during the QA sessions.
On the screen for this part of the lecture I had two windows:
To the left I had a text editor (you can use any good text editor for writing SQL and Python code, I think VS Code is a safe bet – personally I use Emacs, and it's great, but it comes with some big caveats).
In the text editor I edited the SQL scripts (
queries.sqlandcreate-colleges.sql), and the Python program (client.py).- To the right I had a window in which I ran a command line interpreter (CLI) – it is a program which reads commands and executes programs (this program is often called a shell, and there are many to choose from, and the're very similar to each other – if you're running Windows you can use PowerShell, on Mac you can use whatever runs in your Terminal program, and if you're on Linux (as I am), you can use
bash,zsh,fish, or whatever).
I started the SQLite 'client' by issuing the command sqlite3 in my CLI (the rightmost window) – first I did it without giving any filename:
$ sqlite3 SQLite version 3.47.2 2024-12-07 20:39:59 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. sqlite>
Changes we do here will just be saved to an in-memory database, and we
would lose all our data when we exited (unless we explicitly save it,
see below).
To use a specific file to save our database, we just enter it as we start sqlite3:
$ sqlite3 lect02.sqlite SQLite version 3.47.2 2024-12-07 20:39:59 Enter ".help" for usage hints. sqlite>
Here we can do two different kind of things:
- We can enter SQL commands – these are the common suspects,
SELECT,CREATE, etc. We can enter SQLite commands – these are commands for reading from files, saving to files, etc, they're all prefixed by a
., so to read a database from the filelect02.sqlite(from lecture 2), we write (sqlite>is just the prompt):sqlite> .open lect02.sqlite
There are many useful
sqlite3commands, during the lecture I used:.schema, which shows how our tables are defined.print, which prints a message when we run a script.mode, which alters the output format of our queries (we tried columns, boxes and html).drop(see below)
During lecture 2, we looked at an example with college applications, they are in the tables students, colleges, and applications, and we can use the sqlite3 command .dump to see SQL statements which would define the same tables, and the data in them:
$ sqlite3 lect02.sqlite
SQLite version 3.47.2 2024-12-07 20:39:59
Enter ".help" for usage hints.
sqlite> .dump students colleges applications
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE students(
s_id INTEGER,
s_name TEXT,
gpa REAL,
PRIMARY KEY (s_id)
);
INSERT INTO students VALUES(123,'Amy',3.899999999999999912);
INSERT INTO students VALUES(234,'Bob',3.600000000000000088);
INSERT INTO students VALUES(345,'Craig',3.5);
INSERT INTO students VALUES(456,'Doris',3.899999999999999912);
INSERT INTO students VALUES(543,'Craig',3.399999999999999912);
INSERT INTO students VALUES(567,'Edward',2.899999999999999912);
INSERT INTO students VALUES(654,'Amy',3.899999999999999912);
INSERT INTO students VALUES(678,'Fay',3.799999999999999823);
INSERT INTO students VALUES(765,'Jay',2.899999999999999912);
INSERT INTO students VALUES(789,'Gary',3.399999999999999912);
INSERT INTO students VALUES(876,'Irene',3.899999999999999912);
INSERT INTO students VALUES(987,'Helen',3.700000000000000177);
CREATE TABLE colleges(
c_name TEXT,
state TEXT,
enrollment INT,
PRIMARY KEY (c_name)
);
INSERT INTO colleges VALUES('Stanford','CA',15000);
INSERT INTO colleges VALUES('Berkeley','CA',36000);
INSERT INTO colleges VALUES('MIT','MA',10000);
INSERT INTO colleges VALUES('Cornell','NY',21000);
CREATE TABLE applications(
s_id INTEGER,
c_name TEXT,
major TEXT,
decision CHAR(1) DEFAULT 'N',
PRIMARY KEY (s_id, c_name, major),
FOREIGN KEY (s_id) REFERENCES students(s_id),
FOREIGN KEY (c_name) REFERENCES colleges(c_name)
);
INSERT INTO applications VALUES(123,'Stanford','CS','Y');
INSERT INTO applications VALUES(123,'Stanford','EE','N');
INSERT INTO applications VALUES(123,'Berkeley','CS','Y');
INSERT INTO applications VALUES(123,'Cornell','EE','Y');
INSERT INTO applications VALUES(234,'Berkeley','biology','N');
INSERT INTO applications VALUES(345,'MIT','bioengineering','Y');
INSERT INTO applications VALUES(345,'Cornell','bioengineering','N');
INSERT INTO applications VALUES(345,'Cornell','CS','Y');
INSERT INTO applications VALUES(345,'Cornell','EE','N');
INSERT INTO applications VALUES(678,'Stanford','history','Y');
INSERT INTO applications VALUES(987,'Stanford','CS','Y');
INSERT INTO applications VALUES(987,'Berkeley','CS','Y');
INSERT INTO applications VALUES(876,'Stanford','CS','N');
INSERT INTO applications VALUES(876,'MIT','biology','Y');
INSERT INTO applications VALUES(876,'MIT','marine biology','N');
INSERT INTO applications VALUES(765,'Stanford','history','Y');
INSERT INTO applications VALUES(765,'Cornell','history','N');
INSERT INTO applications VALUES(765,'Cornell','psychology','Y');
INSERT INTO applications VALUES(543,'MIT','CS','N');
COMMIT;
sqlite>
We saw that we can also run SQL commands and SQLite commands given as command line parametrs – this enabled me to write:
$ sqlite3 lect02.sqlite ".dump students colleges applications" > create-college.sql
which created a simple textfile create-college.sql with the SQL statements above (the > is a redirection command, which takes the output of one command and saves it in a text file).
Given this file we could create a new database, with only the three tables above (now using <, which sends the content of a text file as input to another command):
$ sqlite3 colleges.sqlite < create-colleges.sql
and we could then see all the students:
$ sqlite3 colleges.sqlite SQLite version 3.47.2 2024-12-07 20:39:59 Enter ".help" for usage hints. sqlite> SELECT * FROM students; s_id s_name gpa ---- ------ --- 123 Amy 3.9 234 Bob 3.6 345 Craig 3.5 456 Doris 3.9 543 Craig 3.4 567 Edward 2.9 654 Amy 3.9 678 Fay 3.8 765 Jay 2.9 789 Gary 3.4 876 Irene 3.9 987 Helen 3.7 sqlite>
We then used the text editor (to the left of the screen) to write a script which showed the names and grades for all students who had applied for Computer Science in California.
I wrote it in a text file called queries.sql, and the SQL code was:
.mode box
.print Applied for CS in California
SELECT DISTINCT s_id, s_name
FROM students
JOIN applications USING (s_id)
JOIN colleges USING (c_name)
WHERE major = 'CS' AND state = 'CA';
I ran this by issuing the command sqlite3 colleges.sqlite < queries.sql in the CLI window (on the right side of the screen):
$ sqlite3 colleges.sqlite < queries.sql Applied for CS in California ┌──────┬────────┐ │ s_id │ s_name │ ├──────┼────────┤ │ 123 │ Amy │ │ 876 │ Irene │ │ 987 │ Helen │ └──────┴────────┘
We also tried to inflate the grades by 10% for all students who had applied for Electrical Engineering (below is the text in the file queries.sql, which I wrote in my text editor):
.mode box
.print Applied for CS in California
SELECT DISTINCT s_id, s_name
FROM students
JOIN applications USING (s_id)
JOIN colleges USING (c_name)
WHERE major = 'CS' AND state = 'CA';
.print Before grade inflation
SELECT *
FROM students;
UPDATE students
SET gpa = min(4.0, gpa * 1.1)
WHERE s_id IN (SELECT s_id
FROM applications
WHERE major = 'EE');
.print After grade inflation
SELECT *
FROM students;
and the results were:
$ sqlite3 colleges.sqlite < queries.sql Applied for CS in California ┌──────┬────────┐ │ s_id │ s_name │ ├──────┼────────┤ │ 123 │ Amy │ │ 876 │ Irene │ │ 987 │ Helen │ └──────┴────────┘ Before grade inflation ┌──────┬────────┬─────┐ │ s_id │ s_name │ gpa │ ├──────┼────────┼─────┤ │ 123 │ Amy │ 3.9 │ │ 234 │ Bob │ 3.6 │ │ 345 │ Craig │ 3.5 │ │ 456 │ Doris │ 3.9 │ │ 543 │ Craig │ 3.4 │ │ 567 │ Edward │ 2.9 │ │ 654 │ Amy │ 3.9 │ │ 678 │ Fay │ 3.8 │ │ 765 │ Jay │ 2.9 │ │ 789 │ Gary │ 3.4 │ │ 876 │ Irene │ 3.9 │ │ 987 │ Helen │ 3.7 │ └──────┴────────┴─────┘ After grade inflation ┌──────┬────────┬──────┐ │ s_id │ s_name │ gpa │ ├──────┼────────┼──────┤ │ 123 │ Amy │ 4.0 │ │ 234 │ Bob │ 3.6 │ │ 345 │ Craig │ 3.85 │ │ 456 │ Doris │ 3.9 │ │ 543 │ Craig │ 3.4 │ │ 567 │ Edward │ 2.9 │ │ 654 │ Amy │ 3.9 │ │ 678 │ Fay │ 3.8 │ │ 765 │ Jay │ 2.9 │ │ 789 │ Gary │ 3.4 │ │ 876 │ Irene │ 3.9 │ │ 987 │ Helen │ 3.7 │ └──────┴────────┴──────┘
In lab 2 you'll have to create your own database file, and then sqlite3 will be invaluable.
SQL in Java
Up until a few years ago, all students did lab 3 and the project in Java, and some knowledge of JDBC is still part of the course, but things are sooo much easier in Python, and using Python lets us focus on what's most important for the course. So for the last couple of years, I've recommended the students to use Python instead of Java, and for at least the last two years, all groups have used Python.
During the corresponding lecture in previous years, I implemented a Java program which used the student database to run some SQL scripts, but this year I decided to just give you a few glimpses (writing the Java program during the lectures took too much time, given that no one actually used Java anyways). So below is a description of how I implemented the Java client last year (you can just skim over it, to get an idea of what's going on).
Below this section, there is a section describing how to do the same thing in Python.
JDBC by example
Some of the slides describe JDBC – we saw that some of the most important interfaces/classes are:
Connection: keeps track of a session to our database (typically we enter a user id and a password, for SQLite it's much easier than that).Statement: a simple class which lets us send SQL commands to our database – we create it with the call:Statement s = conn.createStatement();
or, using Java's syntax for local variables with type inference:
var s = conn.createStatement();
PreparedStatement: a safer and more performant version ofStatement, we create it with:var ps = conn.prepareStatement(sql);
where
sqlis aStringwith the statement or query we want to execute.ResultSet: an object which keeps track of the result of a query. Logically it's a kind of iterator (although it doesn't implement any iterator interface), we step through its rows using calls ofnext()– when there are no more rows to see,next()returnsfalse, but until then, we can use various getters to fetch columns based either on their name, or on their position (see below).
A simple way to keep everything database related in one place is to write a class Database like this (this is the file I put into my project after I had set it up – see below):
package demo;
import java.sql.*;
import java.util.*;
/**
* Database is an interface to the college application database, it
* uses JDBC to connect to a SQLite3 file.
*/
public class Database {
/**
* The database connection.
*/
private Connection conn;
/**
* Creates the database interface object. Connection to the
* database is performed later.
*/
public Database() {
conn = null;
}
/**
* Opens a connection to the database, using the specified
* filename (if we'd used a traditional DBMS, such as PostgreSQL
* or MariaDB, we would have specified username and password
* instead).
*/
public boolean openConnection(String filename) {
try {
conn = DriverManager.getConnection("jdbc:sqlite:" + filename);
} catch (SQLException e) {
e.printStackTrace();
return false;
} catch (ClassNotFoundException e) {
e.printStackTrace();
return false;
}
return true;
}
/**
* Closes the connection to the database.
*/
public void closeConnection() {
try {
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* Checks if the connection to the database has been established
*
* @return true if the connection has been established
*/
public boolean isConnected() {
return conn != null;
}
/* ================================== */
/* --- insert your own code below --- */
/* ===============================*== */
}
The code above sets up a connection to an SQLite file, if we were to connect to, lets say, a PostgreSQL database, we would have to send our user id and password as parameters to openConnection.
I created a new gradle project in the terminal window:
$ gradle init Select type of project to generate: 1: basic 2: application 3: library 4: Gradle plugin Enter selection (default: basic) [1..4] 2 Select implementation language: 1: C++ 2: Groovy 3: Java 4: Kotlin 5: Scala 6: Swift Enter selection (default: Java) [1..6] 6 Select build script DSL: 1: Kotlin 2: Groovy Enter selection (default: Kotlin) [1..2] 1 Project name (default: java-demo): demo Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes,no] no > Task :init To learn more about Gradle by exploring our Samples at https://docs.gradle.org/8.5/samples/sample_building_swift_applications.html BUILD SUCCESSFUL in 26s 2 actionable tasks: 2 executed
The created directory structure can be seen here (using the tree command):
$ tree . ├── app │ ├── build.gradle │ └── src │ ├── main │ │ ├── java │ │ │ └── demo │ │ │ └── App.java │ │ └── resources │ └── test │ ├── java │ │ └── demo │ │ └── AppTest.java │ └── resources ├── gradle │ └── wrapper │ ├── gradle-wrapper.jar │ └── gradle-wrapper.properties ├── gradlew ├── gradlew.bat └── settings.gradle $
We made some simple changes to the main program (which is in app/src/main/java/demo/App.java), and got:
package demo;
public class App {
public static void main(String[] args) {
new App().run();
}
void run() {
System.out.println("hello, world!");
}
}
The new App().run()-thingy is a quirk of mine, it just feels better
to have an object to work with – the rules for static methods in Java
are sometimes surprising.
Wee also moved the file Database.java (see above) into the app/src/main/java/demo/ directory, and tried to use in our program, but gradle let us know that we need the sqlite-jdbc library, so we looked for it in the maven central repository, and found that we need to add:
implementation group: 'org.xerial', name: 'sqlite-jdbc', version: '3.45.0.0'
into the dependencies section of the app/build.gradle file:
/*
* This file was generated by the Gradle 'init' task.
*
* This generated file contains a sample Java application project to get you started.
* For more details on building Java & JVM projects, please refer to https://docs.gradle.org/8.5/userguide/building_java_projects.html in the Gradle documentation.
*/
plugins {
// Apply the application plugin to add support for building a CLI application in Java.
id 'application'
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
}
dependencies {
// Use JUnit Jupiter for testing.
testImplementation libs.junit.jupiter
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation group: 'org.xerial', name: 'sqlite-jdbc', version: '3.45.0.0'
// This dependency is used by the application.
implementation libs.guava
}
// Apply a specific Java toolchain to ease working on different environments.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
application {
// Define the main class for the application.
mainClass = 'demo.App'
}
tasks.named('test') {
// Use JUnit Platform for unit tests.
useJUnitPlatform()
}
For our first JDBC example, we wanted to see all students who had applied for CS at Stanford – we started with the following main program:
First we used some 'wishful thinking', and added some code to run():
package demo;
public class App {
public static void main(String[] args) {
new App().run();
}
public void run() {
var db = new Database();
db.openConnection("colleges.sqlite");
var applicants = db.findApplicants("Stanford", "CS");
for (var a : applicants) {
System.out.printf("%6d: %-20s (%.1f)\n",
a.id,
a.name,
a.gpa);
}
}
}
To get the data from the database we can use the same query we had above – here I've :
SELECT s_name, gpa
FROM students
JOIN applications USING (s_id)
WHERE c_name = 'Stanford'
AND major = 'CS';
but to run it from Java code, we need to create a statement, run the
query through it, and then collect the data from the returned
ResultSet.
The general outline of a JDBC query is (using a PreparedStatement, if
we have no parameters, we can use a Statement instead):
var found = new ArrayList<...>();
var query =
"""
SELECT ...
""";
try (var ps = conn.prepareStatement(query)) {
ps.setString(1, ...); // set parameters...
var resultSet = ps.executeQuery();
while (resultSet.next()) {
// extract the values in rs into an object,
// and then add the object to our list of
// found values
found.add(...(resultSet));
}
} catch (SQLException e) {
e.printStackTrace();
}
return found;
There are many ways of extracting data from our ResultSet, the way I personally prefer is to use a simple POJO (short for Plain Old Java Object), and unpack the columns of a row in the ResultSet into corresponding final attributes in the class.
This is what is sometimes called a 'data class' (or 'record'), and we find nice support for them in Java-related languages such Scala and Kotlin, but
only recently has Java embraced them, and since I realize that some of you may not use the most recent Java (which by now is 21), I'll continue just using simple classes.
A simple POJO for our query is the following:
class Applicant {
public final int id;
public final String name;
public final double gpa;
private Applicant (int id, String name, double gpa) {
this.id = id;
this.name = name;
this.gpa = gpa;
}
public static Applicant fromRS(ResultSet rs) throws SQLException {
return new Applicant(rs.getInt("s_id"),
rs.getString("s_name"),
rs.getDouble("gpa"));
}
}
I've written a simple tool, db-pojo, which lets me define the class in the following way:
Applicant s_id -> id : int s_name -> name : String gpa : double
The first line gives the name of the POJO class, then there is one line per column in the output of the SELECT statement, each column corresponds to an attribute in our generated POJO class. For column names which will be useful attribute names, I only define their type – for column names I don't want as attribute names, I use an arrow to give a better attribute name (of course I could also have used an alias in the SELECT statement to do the same thing).
Since I run Linux, I started db-pojo like this (<CTRL-D> means that
I pressed Control-D – the program then printed the generated class):
$ db-pojo -j
Applicant
s_id -> id : int
s_name -> name : String
gpa : double
<CTRL-D>
class Applicant {
public final String id;
public final String name;
public final double gpa;
private Applicant (String id, String name, double gpa) {
this.id = id;
this.name = name;
this.gpa = gpa;
}
public static Applicant fromRS(ResultSet rs) throws SQLException {
return new Applicant(rs.getString("s_id"), rs.getString("s_name"), rs.getDouble("gpa"));
}
}
This should work for Macs as well, for Windows you might have to start the command as:
$ python db-pojo -j
The program generates the class above (the -j flag tells the program to generate the fromRS-method, there is also a -g flag to generate JSON converters – I'll talk more about that in lecture 6) – you can download my little script here (it's just a quick hack, so please don't read anything into the code – it requires that your computer has Python 3.6+ installed, and by now you should be at 3.10 or 3.11).
Using this 'data class', our query can be implemented as a method in
Database like this (we made the college and the major parameters of
the method):
/* ================================== */
/* --- insert your own code below --- */
/* ===============================*== */
public List<Applicant> findApplicants(String college, String major) {
var found = new ArrayList<Applicant>();
var query =
"""
SELECT s_id, s_name, gpa
FROM applications
JOIN students USING (s_id)
WHERE c_name = ? AND major = ?
""";
try (var ps = conn.prepareStatement(query)) {
ps.setString(1, college);
ps.setString(2, major);
var resultSet = ps.executeQuery();
while (resultSet.next()) {
found.add(Applicant.fromRS(resultSet));
}
} catch (SQLException e) {
e.printStackTrace();
}
return found;
}
As we saw above, this method can be called from App as:
void run() {
var db = new Database();
db.openConnection("colleges.sqlite");
var applicants = db.findApplicants("Stanford", "CS");
for (var a : applicants) {
System.out.printf("%3d: %20s %.1f\n",
a.id,
a.name,
a.gpa);
}
}
The method returns a list of POJO's (Applicant), and we can easily fetch their attributes.
We ran the program using gradle, and since I use Linux, i wrote:
$ ./gradlew run > Task :app:run 123: Amy 3.9 876: Irene 3.9 987: Helen 3.7 BUILD SUCCESSFUL in 795ms 2 actionable tasks: 1 executed, 1 up-to-date
This should work on a Mac as well, on Windows you can run a gradle project with the command:
$ gradlew run
I've been asked the (very good) question why we don't just return the ResultSet objects themselves from the query functions in Database, and the answer is that it could work, but it would be against the Single Responsibility Principle, which states that a package or class ideally should have the responsibility for one thing, and handle everything which has to do with that thing (the latter part is often forgotten – you'll learn more about it in EDAF60).
Breaking the principle would mean that the Database class and the calling class (App in this case) would be very tightly coupled, since the calling class would have to know exactly how the query was stated (i.e., what we called the returned values in our query) – a small change in one class could easily affect the other class, and it would make the code brittle.
One might argue that the same holds for Database and Applicant, but at least they would be part of the same package.
Next we wanted to try an SQL UPDATE, and I intended to write a method which inflates the grades for all students who had applied for a given major – since we were running low on time, I skipped to talking about Python instead, but promised to show how to inflate grades in Java in these notes, so here we go:
public void inflateGrades(String college, double percentage) {
var factor = 1.0 + percentage / 100.0;
var statement =
"""
UPDATE students
SET gpa = min(4.0, gpa * ?)
WHERE s_id IN (
SELECT DISTINCT s_id
FROM applications
WHERE c_name = ?
)
""";
try (var ps = conn.prepareStatement(statement)) {
ps.setDouble(1, factor);
ps.setString(2, college);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
Calling SQLite from Python
In Python, everything we did above becomes much less verbose – during the lecture we wrote a program which found all students applying to a given major in a given state (the same problem which we solved in our script above, but then we hard coded the major and state).
As in Java, we need a connection to our database, in Python we can import the sqlite3 library, and write:
import sqlite3
db = sqlite3.connect('colleges.sqlite')
Now db is connected to our database, and we can create a cursor in which we can execute SQL statements using the execute command:
c = db.cursor()
We wrote a Python function find_applicants(major, state) to look for all applications for a given major in a given state:
def find_applicants(major, state):
...
In this case we want to use the SQL command
SELECT DISTINCT s_id, s_name
FROM students
JOIN applications USING (s_id)
JOIN colleges USING (c_name)
WHERE major = ? AND state = ?;
where the two question marks should be replaced by the major and state, respectively. We do this by adding a list with values to be injected into command:
c.execute(
'''
SELECT DISTINCT s_id, s_name
FROM students
JOIN applications USING (s_id)
JOIN colleges USING (c_name)
WHERE major = ? AND state = ?;
''', [major, state]
)
The result of this is that the cursor c will be an iterator with tuples describing the results of the SELECT statement – in this case we get 2-tuples with ids and names, and we can unpack them with:
for s_id, s_name in c:
print(f'{s_id}: {s_name}')
So, the whole program was:
import sqlite3
db = sqlite3.connect('colleges.sqlite')
def find_applicants(major, state):
c = db.cursor()
c.execute(
'''
SELECT DISTINCT s_id, s_name
FROM students
JOIN applications USING (s_id)
JOIN colleges USING (c_name)
WHERE major = ? AND state = ?;
''', [major, state]
)
for s_id, s_name in c:
print(f'{s_id}: {s_name}')
def main():
find_applicants('CS', 'CA')
main()
At least I think it's hard to imagine a simpler way to call SQL code from another language!
When we ran the program, we got:
$ python client.py 123: Amy 876: Irene 987: Helen
We then tried to add students to the database, and ended up with (we did some initial experimenting – if you have any questions, I'd be happy to answer them at the QA session):
import sqlite3
db = sqlite3.connect('colleges.sqlite')
def add_student(s_id, s_name, gpa):
c = db.cursor()
try:
c.execute(
'''
INSERT
INTO students(s_id, s_name, gpa)
VALUES (?, ?, ?)
''', [s_id, s_name, gpa]
)
db.commit()
except sqlite3.IntegrityError as e:
print('The student id {s_id} is already in use...')
def main():
s_id = int(input('s_id: '))
s_name = input('s_name: ')
gpa = float(input('gpa: '))
add_student(s_id, s_name, gpa)
main()
Here we must be careful to call db.commit() after we've updated the database – we'll talk more about this in week 5.
Finally we tried to find the programs (i.e., major/college) with the highest grade for a rejection:
import sqlite3
db = sqlite3.connect('colleges.sqlite')
def cruellest_rejections(state):
c = db.cursor()
c.execute(
'''
SELECT c_name, major, max(gpa)
FROM students
JOIN applications USING (s_id)
JOIN colleges USING (c_name)
WHERE decision = 'N' AND state = ?
GROUP BY c_name, major
ORDER BY max(gpa) DESC
LIMIT 3
''', [state]
)
for c_name, major, gpa in c:
print(f'{c_name}/{major} - {gpa}')
def main():
state = input('State: ')
cruellest_rejections(state)
main()
You don't have to learn Python for this course, but it undeniably makes some things much easier, and it's worth looking into when you get the time – I'd be happy to try to help you during the QA-sessions.