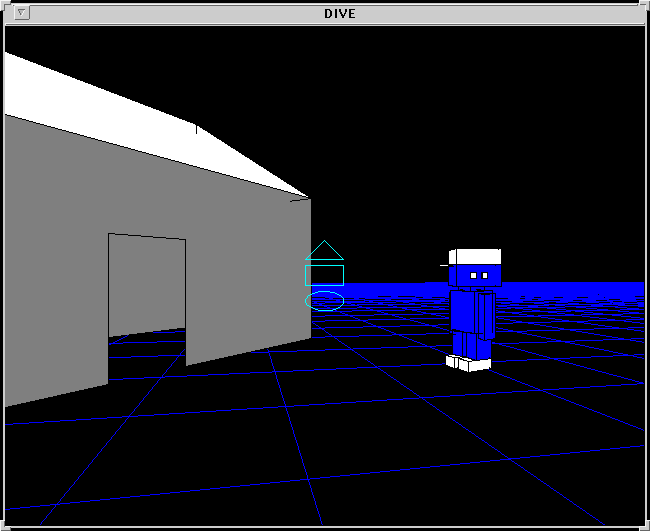
Figure 1: un monde de DIVE avec deux utilisateurs connectés
REVOLTA-BLAUDEAU Frédéric
ISMRA - ENSI de CAEN
Filière Génie Informatique
Année1994-1995
de
fin d'études d'ingénieur
NAVIGATION DANS LES MONDES VIRTUELS
Résolution des références, raisonnement
géométrique et exécution d'actions
Au Laboratoire M. Pierre Nugues, Maître de Conférence
Je tiens tout d'abord à remercier
Christophe Godéreaux, pour m'avoir apporté toute son expérience de DIVE, pour son aide et pour sa constante disponibilité,
Pierre-Olivier El-Guedj pour ses explications sur l'analyseur syntaxique, ses idées,
et Pierre Nugues pour toutes ses idées, ses conseils, ses techniques, sa méthode.
Le but de ce stage est de réaliser un prototype d'agent
d'aide à la navigation dans un monde virtuel, la navigation
se révélant être l'un des points les plus
délicats pour les nouveaux utilisateurs de ce type d'environnement.
Ce stage, qui durera six mois, s'intègre dans un projet
de réalisation d'un agent conversationnel pour le programme
COST-14 de la Commission des communautés européennes
sur le travail coopératif à l'aide de l'ordinateur
DIVE. Les entités du prototype
déjà réalisés ont pour rôle
de traîter l'analyse syntaxique et sémantique. Les
modules qui nous intéressent ici sont ceux du gestionnaire
d'actions qui permet d'exécuter les ordres de navigation
d'un utilisateur. Ce gestionnaire utilise module de résolution
des références et module de raisonnement géométrique.
Le système résultant s'intégrera dans un
outil de téléconférence.
DIVE, Distributed Interactive Virtual Environment, est un environnement virtuel réparti. Il se fonde sur le système d'exploitation Unix et les protocoles Internet [ANDERSON 94]. Il a été développé par le Swedish Institute of Computer Science (SICS), membre de COST 14. Il a notamment comme but d'être un outil de téléconférence.
L'environnement DIVE s'articule autour d'une base de donnée géométrique partagée. Il est constitué de processus pouvant être soit des utilisateurs humains soit des automates. Lorsque l'utilisateur est connecté à DIVE par le réseau Internet, il est représenté graphiquement par un agent virtuel disposant d'un véhicule. Ce véhicule est représenté sur l'écran par trois icônes attachées à trois modes de déplacement (voir tableau 1).
Type de déplacements Icônes Représentation
déplacement dans le plan
horizontal:
un axe de translation, un axe de
rotation déplacement dans le plan
vertical:
deux axes de translations deux axes de rotations
Un utilisateur peut voir, rencontrer (figure 1), collaborer avec d'autres participants pouvant être des utilisateurs ou des applications. Une application est un automate qui a pour but de contrôler des tâches simples et/ou de répondre à des interactions avec les utilisateurs.
Conceptuellement, ce système peut se décrire comme une mémoire partagée par un ensemble de processus interagissant sur celle-ci (voir figure 2). Cette mémoire partagée se répartit en mondes. Chaque monde représente un ensemble spécifique d'objets et de paramètres complètement distincts des autres mondes. Un processus de DIVE est un membre d'exactement un seul monde mais il peut changer dynamiquement de monde. Lorsque l'utilisateur se connecte à DIVE, il perçoit et interagit sur le monde par l'intermédiaire de dispositifs matériels ou logiciels. Ces dispositifs sont gérés par des applications. Ils permettent la visualisation (sur un écran, un visiocasque...), l'interaction tactile (Data Glove, souris), la gestion d'ascenseurs, d'agents virtuels...
Figure 2: le fonctionnement conceptuel de DIVE.
Tout d'abord, un corpus de dialogues a été réuni afin d'étudier l'utilisation de la langue orale dans ces environnements virtuels. Cette démarche est cruciale pour identifier les problèmes n'apparaissant pas dans la réalité et laisser de côté ceux ne semblant intéressants que dans l'abstrait [ALLEN 94]. Pour chaque dialogue, une personne joue le rôle de l'utilisateur et une autre celui de l'agent virtuel. Ces dialogues sont enregistrés sur bandes magnétiques et retranscrits sur machine. Quatre dialogues d1, d2, d3 et d4 ont été collecté avec à chaque fois un utilisateur différent. C'est à partir de ces corpus que j'ai construit la présente application, [GODEREAUX 95] soumis.
A nous sommes connectés au monde robot. U8 tourne sur toi-même. A vers la droite ou vers la gauche? U9 vers la droite. A voilà. U10 prends de la hauteur. U11 arrête de monter. U12 monte. A oui. U13 stop. Figure 3 : Extrait 1 du dialogue d4
U45 va jusque là.
A je me dirige vers la montagne.
U46 fait le tour de la montagne.
A oui.
U47 retourne sur l'île précédente
A je ne connais pas l'île précédente.
U48 regarde à droite.
A voilà.
U49 encore.
U50 c'est ici.
A je me dirige vers la montagne.
Figure 4 : Extrait 2 du dialogue d4
Le système se compose d'un analyseur syntaxique, d'un analyseur sémantique, d'un gestionnaire de dialogues, d'un gestionnaire d'actions, un résolveur de référence et un raisonneur géométrique (figure 5). J'ai réalisé les 3 derniers. Les trois premiers, plus spécifiques au traitement linguistique, ont été réalisés par Pierre-Olivier El-Guedj et Christophe Godéreaux.
L'analyseur syntaxique est fondé sur les techniques de Chart [EL GUEDJ 94], et utilise un lexique fondé sur l'analyse des corpus. Il accepte des treillis de mots permettant le traitement en parallèle de plusieurs hypothèses lexicales. Il utilise des grammaires syntagmatiques et des dépendances enrichies d'équations d'unification. Pour cette application, nous nous sommes restreints à une grammaire syntagmatique du fait de la brièveté des énoncés à analyser. L'analyseur accepte les mots séquentiellement et les analyse au fur et à mesure de leur énonciation jusqu'à ce que la phrase soit complète.
L'analyseur sémantique décompose le Chart, retourné par l'analyseur syntaxique, en une liste d'actions. D'après les énoncés qui apparaissent dans notre corpus, cette décomposition dépend de plusieurs paramètres :
· le nombre de propositions et leur fonction dans l'énoncé.
· le nombre de verbes dans chaque proposition et la fonction de chacun de ces verbes: s'il dirige la proposition principale, s'il appartient à un complément de circonstance...
Nous utilisons une grammaire de cas afin de représenter sémantiquement une action sous la forme de structure prédicative. Ceci s'inspire du système de dialogue EVAR [MAST 93]. Le verbe de l'action correspond au nom du prédicat. Les autres constituants de la phrase sont associés aux paramètres de la structure prédicative. Par exemple, le verbe “ monter ” et le verbe “ regarder ” sont associés aux prédicats:
monter([sens, ALLER],[lieu_par_defaut, EN_HAUT]).
regarder([sens,REGARDER],[lieu_par_defaut, EN_AVANT]).
Ce qui est fourni par l'analyseur sémantique présente un certain nombre de références ambiguës. Elles sont résolues par le résolveur de références. Une fois la liste d'actions déterminée sans ambiguïté, elle est transmise au gestionnaire d'actions. Si ces actions sont exécutables, le gestionnaire de dialogues acquiescera l'ordre de l'utilisateur par un message positif aléatoire. Dans le cas contraire le gestionnaires de dialogues signalera oralement la cause de la non-exécution de l'ordre. La synthèse orale permettra à l'utilisateur de modérer son attention visuelle ordinairement accaparée par le flot continu d'images.
Le gestionnaire d'actions vérifiera et exécutera les actions transmises par l'analyseur sémantique.
Figure 5: architecture du prototype
Pour l'instant, l'interfaçage entre l'analyseur sémantique
et le gestionnaire d'actions n'est pas réalisée
car l'analyseur sémantique n'est pas totalement terminé.
Le gestionnaire n'accepte, pour le moment, que des phrases simples
du type verbe-préposition-nom et éventuellement
un adjectif se rapportant à ce nom. Il utilise un résolveur
de références et un module de raisonnement géométrique.
Associer un nom à un objet est parfois une tâche complexe [KARLGREN 95]. Les utilisateurs peuvent utiliser un vocabulaire différent pour désigner la même chose. Ils peuvent aussi considérer certains objets comme des compositions ou des hiérarchies et des relations entre les objets, alors que dans la base de données, ils forment des entités uniques. Une maison peut se représenter comme un ensemble de lignes polygonales ou bien un ensemble de sous objets tels qu'un toit, une porte, des fenêtres, etc. Ces sous objets étant constitués soit d'autres sous structures, soit des lignes polygonales. De plus, il faut tenir compte de l'orientation des objets : le " devant d'une maison " n'est pas la même chose que le " devant d'un cube ".
Dans le prototype présent, les objets sont des entités
géométriques (figure 6) de la base de données
du monde auxquelles on associe un concept par exemple maison.
Ce nommage est bien sûr dépendant de la structure
de la base de données géométrique. Nous avons
cherché à établir les correspondances les
plus pertinentes en fonction de notre corpus. Les objets du monde
sont identifiés de manière unique et sans hiérarchie
par deux paramètres: un nom choisi pour désigner
l'objet correspondant aux mots utilisés dans le corpus,
par exemple cube, maison, voiture et un numéro (cube
numéro 1, cube numéro 2, ...). Si un utilisateur
n'utilise pas ce nom, il faudra résoudre le problème
par le dialogue.
Figure 6: définition d'un cube bleu pour DIVE
Pour ce qui concerne l'orientation, nous avons cherché
à respecter un principe unique : si on peut aller à
l'intérieur de l'objet, le centre de son référentiel
est au centre de l'objet et c'est l'endroit où sera placé
l'utilisateur s'il demande à rentrer à l'intérieur.
Il faut donc le définir judicieusement. De plus, pour repérer
sa face de devant s'il en a une, l'axe des z de son référentiel
est orienté vers cette face.
Le monde virtuel actuel se compose des objets suivants:
Les références et les désignations ambiguës
sont multiples dans les corpus. Elles proviennent notamment de
références déictiques
prends ça
ou de possibilité de choix multiples
va vers la maison (parmi plusieurs)
La résolution de référence a été
étudiée dans la littérature [KARLGREN 95]
utilise le focus, [HULS 95] utilise une salience value
pour résoudre les références et les anaphores.
Cette salience value, propre à un objet, est calculée
par une somme de poids, dépendant du contexte (par exemple
dépendant de la visibilité, du fait que des objets
aient été désignés explicitement...),
sur chaque instance de la classe à laquelle appartient
l'objet considéré. Les pluriels sont gérés
par des ensembles. Elle distingue les références
de personnes, de temps et d'espace. Finalement, elle conclut que
son système n'a pas encore prouvé sa supériorité
par rapport à d'autres plus complexes, mais il donne déjà
de bons résultats et il est relativement simple à
mettre en œuvre.
De notre côté, pour lever ces ambiguïtés
de désignations, nous avons utilisé deux critères:
Le fait qu'un objet soit dans le champ de vision de l'utilisateur
ou non.
Un focus dont on a pourvu chaque objet. Le focus s'inspire de
[KARLGREN 95]. Il consiste en un coefficient mis à jour
en fonction des interactions de l'utilisateur. Il permet de résoudre
d'une manière simple les ambiguïtés de désignation.
Pour chaque utilisateur, chaque objet du monde dispose d'un focus
- un nombre entier -. Le focus d'un objet devient majorant de
tous les autres lorsque l'utilisateur clique sur cet objet (désignation
sans équivoque) ou lorsqu'il le désigne dans une
phrase.
L'algorithme de résolution des références
fonctionne différemment suivant que l'utilisateur mentionne
ou non explicitement un objet.
1. Lorsque l'utilisateur a énoncé un nom d'objet,
on établit une liste compatible avec l'énoncé.
De plus, le module vérifie la concordance des adjectifs
: (par exemple " avance vers le cube rouge ").
Soit il ne reste qu'un objet dans ce cas la résolution
est terminée, soit il en reste plusieurs. Si le focus de
l'un d'eux est majorant, on choisit cet objet et la référence
est terminée. Sinon, on considère le verbe utilisé.
Nous avons catégorisé des couples verbes-prépositions
en deux ensembles, l'un indiquant une position par rapport à
l'axe de vision de l'utilisateur et l'autre indiquant un objet
déjà désigné:
· Les verbes du type " va vers ", "
avance devant ", " entre dans " "
tourne-toi vers le cube " signifient que l'objet est
visible et sans doute dans l'axe de mouvement de l'utilisateur,
tous les objets non visibles sont donc éliminés.
S'il reste plus d'un objet, la résolution n'est pas possible
et l'agent informe l'utilisateur qu'il ne sait pas quel objet
choisir.
· Pour les autres verbes comme " retourne vers ",
" reviens devant " par exemple avec la phrase:
" retourne vers la maison ", la visibilité
n'entre pas en compte. On considère alors le focus et sélectionne
l'objet compatible dont le focus est le plus élevé.
Ce choix correspond à l'intuition suivante : l'utilisateur
désigne sans doute le dernier des objets - ici une des
maisons - vers laquelle il s'est précédemment dirigé.
Dans ce cas le focus de cette maison est le plus élevé.
2. Lorsque l'utilisateur ne spécifie pas explicitement
de nom d'objet (par exemple " avance devant ",
" regarde le "). On recherche alors l'objet dont
le focus est le maximum parmi tous les focus. Ceci correspond
généralement à un objet mentionné
dans la phrase précédente ou à un objet désigné
à la souris. Dans ces deux cas l'objet aura le focus maximal.
Si aucun objet n'est trouvé (tous les focus sont à
zéro, ou plusieurs focus ont une valeur maximale, dans
le cas de pluriels qui n'est pas encore traîté) on
indique à l'utilisateur qu'on ne comprend pas de quel objet
il s'agit.
Le module de raisonnement géométrique intervient
comme intermédiaire entre les énoncés de
l'utilisateur et le monde virtuel. Il constitue la principale
entité de raisonnement de l'agent. Nous présentons
ici le raisonnement que cet agent met en œuvre lorsque l'utilisateur
lui donne des ordres de navigation. Ces ordres consistent dans
des énoncés qui contiennent toujours un verbe. Pour
l'instant, nous distinguons six catégories de verbes. Les
deux premières correspondent à la catégorie
Change of Locations citée par Sablayrolles, les
deux catégories suivantes sont apparues dans le corpus,
les deux dernières correspondent à la catégorie
Change of Postures de Sablayrolles [SABLAYROLLES 95]:
L'algorithme est le suivant :
1. on recherche à quelle catégorie appartient le
verbe.
2. suivant le verbe :
· Si la phrase est du type verbe de déplacement (c'est-à-dire
une des deux premières catégories) - préposition
- objet cible; le module de résolution de référence
est activé. Si un seul objet convient, on passe à
l'analyse de la préposition, sinon (aucun objet ou plus
d'un objet est susceptible de convenir) l'agent en informe l'utilisateur.
· Si le verbe est du type " arrête ",
l'action en cours est simplement arrêtée.
· Si le verbe est du type " continue ",
l'action précédemment en cours est reprise.
· Si le verbe est du type " tourne " ou
" regarde ", deux cas sont possibles: "
tourne vers objet " lancera la résolution de
référence puis la représentation de l'utilisateur
subira une rotation (de la tête ou du corps suivant la catégorie
du verbe) telle que l'objet trouvé soit devant lui, sinon,
il n'y a pas de nom d'objet mais une direction (" tourne
à droite " par exemple), on applique alors à
la représentation la rotation qui convient.
3. Analyse de la préposition dans le cas où le verbe
est " va " ou " retourne " et
où la résolution de référence est
terminée et a abouti (un et un seul objet a été
trouvé), la position à donner à l'utilisateur
pour exécuter son ordre est déterminée en
fonction de la préposition ou de la locution. Pour l'instant,
nous avons traîté :
· devant: nous avons distingué les objets qui
ont un " devant " (maison, voiture...) des objets
qui n'en ont pas (cube, table...). Par exemple, " aller
devant la maison " signifie se placer devant la face
de la maison où apparaît la porte et à une
distance suffisante pour que la maison tienne dans le champ de
vision de l'utilisateur. " Aller devant le cube "
signifie se tourner en direction du cube, avancer jusqu'à
lui et s'arrêter à une distance suffisante. Pour
ceci, chaque objet possède une distance caractéristique
qui indique à quelle distance se placer de l'objet et si
l'objet possède une face ou non. Ainsi, on peut calculer
la position à donner à l'utilisateur et trouver
son " devant ", s'il en a un.
· derrière: nous observons de même que
les objets qui ont un " devant " ont un "
derrière ". On distingue donc encore deux cas
pour calculer la position : " derrière la maison
" signifie devant la face opposée qui contient la
porte (face de devant) et derrière le cube signifie à
l'opposée de la position à laquelle l'utilisateur
se trouve actuellement. On se place à la même distance
que devant l'objet. (on utilise donc la même distance caractéristique
que précédemment).
· vers, jusqu'à, près de: l'agent doit
tourner l'utilisateur en direction de l'objet et le déplacer
à une distance suffisante de l'objet (la même que
précédemment).
· sur: de même que pour la distance, chaque
objet possède une hauteur qui permet de calculer simplement
la position à donner à l'utilisateur par rapport
au référentiel de l'objet pour que celui-ci soit
effectivement sur l'objet. Ce qui fait que " monte sur
la chaise " place l'utilisateur sur le siège de
la chaise.
· dans, à l'intérieur de: l'agent déplace
l'utilisateur jusqu'au centre du référentiel de
l'objet.
· hors de, dehors, à l'extérieur de:
pour l'instant, l'agent se contente de déplacer l'utilisateur
devant l'objet. Ainsi, il sort de l'objet.
· à gauche de, à droite de: on se positionne
sur la droite perpendiculaire au segment passant par le centre
du référentiel de l'objet et le centre du référentiel
du personnage à une distance égale à la distance
caractéristique de l'objet.
4. Analyse de la préposition dans le cas de " tourne
": si la phrase contient un nom d'objet, dans ce cas la résolution
de référence est activée et l'agent appliquera
une rotation à l'utilisateur, soit la phrase contient une
direction, dans ce cas l'agent calcule l'angle correspondant et
appliquera la rotation à l'utilisateur.
Le gestionnaire d'actions opérera régulièrement
des petits déplacements et des petites rotations sur l'utilisateur:
une rotation de la tête vers la direction demandée,
une rotation du corps de l'utilisateur, ensuite elle translate
l'utilisateur d'un petit déplacement élémentaire
en direction du point à atteindre seulement si ce point
est dans le champ de vision de l'utilisateur, ceci pour simuler
le fait que nous nous tournons dans la direction où nous
allons.
Les mondes de la base de données de DIVE sont définis
dans des fichiers. Le problème est que ceux-ci ne contiennent
que des descriptions graphiques des objets et leur nom. Il a donc
fallu d'une part redéfinir entièrement un monde
de façon cohérente et d'autre part créer
un fichier annexe comportant des descriptions supplémentaires
sur les objets de ce monde et gérer ces données
par rapport aux objets du monde.
Un monde de DIVE est constitué de plusieurs référentiels
: le référentiel du monde (ou référentiel
absolu), et les référentiels des autres objets (par
rapport au référentiel du monde), parmi lesquels
les référentiels des utilisateurs (leur corps étant
un objet comme un autre). Ces objets sont définis dans
des fichiers lus par un préprocesseur de langage C et sont
décrits par des primitives : lignes, polygones, cubes (voir
figure 6)... Nous avons constaté que les descriptions des
mondes existants ne sont pas cohérentes. En effet, il arrive
que le référentiel d'un objet ne soit pas translaté
par rapport au référentiel du monde, il en résulte
que la position du cube de gauche de la figure 7 est (0, 0, 0),
ce qui n'est pas souhaitable.
Il a donc fallu totalement redéfinir un monde comportant
des maisons, des cubes, des tables... Nous avons défini
le centre du référentiel au centre de l'objet comme
pour le cube de droite de la figure 7. Nous avons orienté
l'axe des z vers la face avant de l'objet s'il en a une et l'axe
des y soit dirigé vers le haut de l'objet.
Figure 7 : exemple de positionnement de référentiels
d'objets.
Au démarrage de l'application, l'agent virtuel lit un autre
fichier comportant les descriptions supplémentaires des
objets nécessaires au résolveur de références
et au raisonneur géométrique:
nom et numéro de l'objet (cube 1, cube 2, ...) pour relier
ces descriptions supplémentaires à l'objet de la
base de donnée de DIVE.
genre du nom de l'objet (masculin ou féminin).
distance caractéristique de l'objet. C'est-à-dire
la distance à laquelle placer un utilisateur pour qu'il
soit devant l'objet et que cet objet tienne dans son champ de
vision.
hauteur à laquelle placer une personne par rapport à
l'axe des y du référentiel de l'objet (c'est celui
qui est orienté vers le haut) pour que cette personne soit
sur l'objet dans le cas ou elle demanderait à aller sur
l'objet.
liste des adjectifs décrivant cet objet.
Chaque objet de la base de donnée de DIVE est représenté
en mémoire par une structure, pour les besoins des applications
qui utilisent les objets, un pointeur de cette structure est libre.
Ces informations sont donc stockées dans une structure
pointée par le pointeur de l'objet correspondant.
Cette liste est extensible en fonction des besoins. Par exemple,
le paramètre hauteur pose un problème: si un objet
subi une rotation (bien que pour l'instant, aucune application
ne permette ce genre d'opération), il se peut que l'axe
des y de l'objet (qui est normalement orienté vers le haut)
soit orienté dans une tout autre direction comme le montre
la figure 8. Pour résoudre ce problème, on devra
accéder dynamiquement aux coordonnées des primitives
des objets de la base de données de DIVE pour trouver la
surface de l'objet la plus élevée.
Figure 8: le problème de la hauteur des objets.
Le résolveur de références est écrit
en C++, il est appelé par le gestionnaire d'actions lorsqu'un
ordre est reçu. Dans toutes les opérations, le résolveur
s'arrête s'il ne reste qu'un objet, la résolution
est alors terminée. Dans les autres cas (liste vide, ou
contenant plusieurs objets), il faudra résoudre le problème
par le dialogue.
Le résolveur de référence commence par remplir
une liste de pointeurs sur des objets (au sens DIVE) ayant le
nom spécifié dans l'ordre. Il retournera comme résultat
au raisonneur géométrique un pointeur sur un objet.
S'il y a un adjectif, il élimine de la liste tous les objets
ne possédant pas cet adjectif. Il applique ensuite différentes
fonctions dans différents ordres suivant le verbe et la
préposition comme expliqué au paragraphe 2.
Pour la visibilité: pour chaque objet de la liste,
on considère ses coordonnées (c'est-à-dire
les coordonnées de son centre de gravité) dans le
référentiel de la tête (c'est un objet comme
un autre, il possède donc un référentiel)
s'il est dans un cône d'axe l'axe des z de la tête,
et de pente déterminée de manière pragmatique
alors il est considéré comme visible (l'utilisateur
doit le voir sur l'écran), sinon, il est éliminé
de la liste (voir figure 9).
Figure 9: le cône de visibilité
Pour le focus: il suffit de parcourir la liste des focus
des objets et de regarder quel est le plus grand des focus. Si
plusieurs objets ont pour focus le focus majorant, le problème
n'est pas résolu et il faudra utiliser d'autres critères
ou résoudre le problème par le dialogue.
Pour mettre en place ces focus qui dépendent à la
fois de chaque objet et de chaque utilisateur (puisqu'ils dépendent
de ce qu'a dit ou fait l'utilisateur), une liste appartenant à
un unique utilisateur est construite au démarrage de l'agent,
elle contient, pour chaque objet (au sens DIVE), un pointeur sur
cet objet (dans la base de donnée de DIVE) et la valeur
de son focus. Ces focus sont mis à jour lors d'un clique
de l'utilisateur sur un objet ou lorsque la résolution
a abouti et a trouvé un seul objet.
Le raisonneur géométrique est également écrit
en C++. Conformément à l'algorithme décrit
au paragraphe 6, il recherche la catégorie du verbe. Suivant
la catégorie du verbe, il effectue les opérations
suivantes:
Si le verbe est du type " va " ou " retourne
", le résolveur de référence est appelé,
qu'un nom d'objet soit spécifié (" va devant
la maison ") ou non (" va devant ").
Il calcule ensuite la position où veut se rendre l'utilisateur
par rapport à cet objet (le résolveur de référence
a renvoyé un pointeur sur l'objet de la base de donnée
de DIVE pour que le raisonneur géométrique puisse
accéder aux coordonnées de cet objet) en fonction
de la préposition. Il remplit alors une liste pour savoir
où placer l'utilisateur et dans quel sens orienter son
corps et sa tête, elle est donc propre à chaque utilisateur.
Cette liste sera traîtée par le gestionnaire d'actions
(voir paragraphe suivant). Si l'action à exécuter
est complexe (" fait le tour de la maison "),
elle est décomposée en actions élémentaires.
La liste est donc composée de plusieurs objets (au sens
C++), chacun décrivant une action élémentaire.
Chaque objet est constitué des champs suivants:
1. Le point où l'utilisateur veut se rendre.
Les variables 2, 4 et 6 servent à exécuter les
ordres du type " stop " ou " arrête
" et " continue ". Lorsque l'interfaçage
avec l'analyseur sémantique sera réalisé,
il sera possible d'implanter les ordres du type " arrête
de tourner la tête " ou " arrête
de marcher, continue de regarder à droite " par
exemple.
D'autre part, nous ne tenons pas compte, pour l'instant, des
déplacements des objets : si la maison bouge après
que l'utilisateur ordonne de se placer devant, il se retrouvera
au point initial. Celui qui était devant la maison avant
qu'elle ne bouge.
Dans le cas " regarde " (tourne la tête) ou "
tourne " (tourne le corps), et une direction, la même
liste est remplie par un calcul d'angle (calcul des variables
3 et 5). Si c'est un nom d'objet qui est spécifié
(" regarde la maison "), le résolveur
de référence est appelé et la liste est remplie
de la même manière après calcul.
Les ordres sont donnés par l'intermédiaire d'un
petit programme C qui demande la saisie d'un verbe, d'une préposition
et d'un nom, éventuellement d'un adjectif. Une fois l'ordre
saisi, il l'écrit dans un fichier comme le fera l'analyseur
sémantique, ceci facilitera l'interfaçage final
avec l'analyseur sémantique. L'alarme du gestionnaire d'actions,
appelée toutes les 500 millisecondes, lit ce fichier et
considère que lorsqu'un point apparaît, l'ordre est
complet. Elle déclenche alors le module de résolution
de références (suivant le cas) et le raisonneur
géométrique. Le résultat de ces deux fonctions,
qui sera utilisé par le gestionnaire d'actions, se trouve
alors dans la liste d'objets décrite ci-dessus.
Cette liste d'objets est traîtée par une autre alarme
qui est, elle aussi, déclenchée toutes les 500 millisecondes.
C'est cette alarme qui constitue le gestionnaire d'actions: elle
agit physiquement sur l'utilisateur, elle permet d'obtenir un
déplacement continu.
À chaque appel, l'alarme commence par traîter les
positions de la tête: si le gestionnaire doit accomplir
le mouvement (variable 6 positionnée correctement), il
regarde alors si le corps doit aussi être bougé (variables
2 et 4).
Si non, il applique une petite rotation à la tête
de l'utilisateur dans la direction demandée (champs 5).
Si oui, 2 cas sont à nouveau possibles.
Si la tête et le corps doivent tourner en sens opposé,
l'angle de la rotation appliquée à la tête
(qui est un petit angle pour que la tête tourne lentement)
vaut deux fois l'angle utilisé dans les autres cas. En
effet, le corps (y compris la tête puisqu'elle appartient
au corps) subira par la suite une rotation dans l'autre sens (sens
dans lequel tourner le corps) ce qui aura pour effet de refaire
tourner la tête dans le mauvais sens mais d'un angle plus
petit. Finalement, la tête aura tourné dans le bon
sens.
Si le corps et la tête doivent tourner dans le même
sens, on tourne le corps, la tête est alors également
tournée dans le même sens.
Ensuite, le gestionnaire traîte les variables 3 et 4 et
applique une petite translation au personnage en direction du
point à atteindre.
Quand l'action est terminée, il en informe l'utilisateur.
Pour tester si la liste d'actions est bien gérée,
le gestionnaire d'actions accepte aussi l'ordre dont le verbe
est " fait le tour ", la préposition est "
de ", et un nom d'un objet. La liste est alors remplie de
4 positions à atteindre (à droite, derrière,
à gauche puis devant l'objet). Le personnage fait alors
correctement le tour de l'objet.
Pour l'instant, seules deux fonctions (test de visibilité
et focus) permettent de réduire la liste initiale d'objets
ayant un nom donné, mais il sera facile de rajouter des
fonctions permettant de résoudre d'autres références
avec d'autres critères, dans d'autres situations quand
l'interfaçage avec l'analyseur sémantique sera implanté,
par exemple pour trouver " le cube de gauche ",
" le cube à droite de la maison " et de
gérer les pluriels " dirige-toi vers les cubes
". D'autres objectifs sont de pouvoir traîter les verbes pronominaux,
les quantités (" regarde plus à droite ")...
Le gestionnaire d'actions permet des échanges tels que
ceux-ci :
Nous avons décrit un gestionnaire d'actions, un raisonneur
géométrique et un résolveur de références
pour un prototype d'agent conversationnel. Ceci permet de naviguer
oralement dans un système de réalité virtuelle.
Ensuite, nous avons décrit l'implantation actuelle de cet
agent.
Ce type d'agent conversationnel offre des perspectives importantes.
Au fur et à mesure de nos tests nous mettons en évidence
de nouveaux besoins, tels que de nouvelles actions de navigation
ou la création d'un agent de manipulation d'objets. Plus
généralement nous pensons que ce type d'agent offre
un cadre d'expérimentation unique pour le dialogue, la
linguistique informatique ou encore le raisonnement géométrique.
[ALLEN 94] J. F. Allen, L. K. Schubert, G. Ferguson, P. Heeman,
C. Hee Hwang, T. Kato, M. Light, N. G. Martin, B. W. Miller, M.
Poesio, D. R. Traum, "The TRAINS Project: A case study in
building a conversational planning agent", TRAINS Technical
Note 94-3, University of Rochester New York, September 1994.
[BENFORD 93] A Spatial Model of Interaction in Virtual Environments,
Proc of the 3rd Conference on CSCW, ECSCW 93, September 1993.
[BURDEA 93] G. Burdea, P. Coiffet, La réalité virtuelle,
Hermes, 1993.
[COTECH 95] Virtual and Augmented Environments for CSCW, http://www.crg.cs.nott.ac.uk/CoTech,
1995.
[EL GUEDJ 94] P. O. El-Guedj, P. Nugues, "A chart parser
to analyse large medical corpora", 16H Annual International
Conference of the IEEE Engineering in Medicine and Biology Society,
pp 1404-1405, November 1994.
[GODEREAUX 95] C. Godéreauw, P. O. El Guedj, F. Revolta-Blaudeau,
P. Nugues, "Un agent conversationnel pour naviguer dans les
mondes virtuels", soumis.
[HULS 95] C. Huls, E. Bos, W. Claassen, "Automatic Referent
Resolution of Deictic and Anaphoric Expressions", Computational
Linguistics, vol. 21, no. 1, March 1995.
[KARLGREN 95] J. Karlgren, I. Bretan, N. Frost, L. Jonsson, Interaction
models, Reference, and Interactivity in Speech Interfaces to Virtual
Environments, Eurographics Workshop, 1995.
[MAST 93] M. Mast, F. Kummert, U. Ehrlich, G. A. Fink, T. Kuhn,
H. Niemann, and G. Sagerer, "A speech understanding and dialog
system with a homogeneous linguistic knowledge base", IEEE
Transactions on pattern analysis and machine intelligence, vol.
16, no. 2, February 1994.
[SABLAYROLLES] P. Sablayrolles, The Semantics of Motion, http://xxx.lanl.gov/cmp-lg, 1995.
}
min_descr "2"
material "BLUE_NEON_M"
translation v -18 0 39
eulerxyz v 0 0.6 0
view 0
{
RBOX
}
v 0.5 1 -0.5
objet possède un devant
et un derrière
maison oui
table non
chaise oui
affiche oui
ordinateur oui
voiture oui
drapeau non
cube non
boule non
sol non
Tableau 2: les objets du monde actuel
5.2. L'algorithme de résolution des références
6. Le module de raisonnement géométrique
Catégorie Verbes Explication
va va, avance, rentre, correspondent à un changement de
monte, approche, marche, lieu avec éventuellement une
pénètre, entre, sors, rotation du personnage
ressors
retourne retourne, reviens Cette catégorie est distincte de la
précédente par le fait que l'objet
devra être recherché par le focus
et non par la visibilité
stop stop, arrête arrêt de l'action en cours
continue continue reprise de cette action
tourne tourne, oblique, pivote, correspondent à une simple rotation
dévie, vire du corps
regarde regarde correspond à une simple rotation de
la tête
7. Implantation
7.1. Redéfinition d'un monde cohérent.
7.2. Descriptions supplémentaires
7.3. Implantation du résolveur de références
7.4. Implantation du raisonneur géométrique
2. Une variable qui indique si le gestionnaire d'actions doit accomplir ce déplacement.
3. Le point vers lequel son corps doit être orienté.
4. Une variable qui indique si le gestionnaire d'actions doit accomplir cette rotation.
5. La direction (par rapport à son corps) vers laquelle il veut regarder. C'est-à-dire l'orientation de sa tête.
6. Une variable qui indique si le gestionnaire d'actions doit accomplir cette rotation.
7.5. Implantation du gestionnaire d'actions
8. Perspectives
9. Exemple de dialogue
Ordres et actions de Réponses de l'agent Séquences
l'utilisateur
Bonjour. Bienvenue dans
le monde Ithaques.
Avance devant la
maison.  Voilà.
Voilà.  Regarde derrière.
Voilà.
Regarde derrière.
Voilà.  Va dans la maison.
Il y a plusieurs
maisons !
(clique de
l'utilisateur sur la
maison de gauche)
Entre dedans.
Voilà.
Va dans la maison.
Il y a plusieurs
maisons !
(clique de
l'utilisateur sur la
maison de gauche)
Entre dedans.
Voilà.  Sors.
Sors.  Va derrière.
Voilà.
Va derrière.
Voilà.  av à droite de la
maison.
Je ne connais pas ce
verbe.
Va à droite de la
maison.
Voilà.
av à droite de la
maison.
Je ne connais pas ce
verbe.
Va à droite de la
maison.
Voilà. 
10. Conclusion
Références