Tentamen i EDAF75, mars 2021 – lösningsförslag
Om tentan
Tentan består rent logiskt av fyra delar:
- Uppgift 1: ER-modellering
- Uppgift 2: SQL
- Uppgift 3: Normalisering
- Uppgift 4-6: Övrigt
Här räknas uppgift 1, 2 och 3 som "konstruktionsuppgifter".
Innan jag började rätta var jag rädd att tentamensresultatet skulle bli sämre på grund av distansundervisningen, men i själva verket har jag aldrig sett så bra lösningar på konstruktionsuppgifterna på en tenta som denna gång – så bra gjort av er!
Nedan finns lösningsförslag till uppgifterna – ni kan se uppgifterna och era egna lösningar på Moodle. Om du vill se ditt eget protokoll, skicka ett mail till Christian från din stil-adress (så att jag vet att det verkligen är du som skriver).
Uppgift 1
(1a)
På vanliga tentor (dvs de som skrivs i tentamenssal) brukar vi i förstauppgiften be att man först redovisar ett ER-diagram, och sedan beskriver de relationer man skapar utifrån detta diagram. På grund av omständigheterna utgick denna gång redovisningen av ER-diagrammet, och vi lät er istället direkt skriva SQL-kod för att implementera de tabeller som er modell ger upphov till.
Jag utgår ifrån (hoppas!) att de flesta av er ritade ett ER-diagram ändå, här är ett förslag:
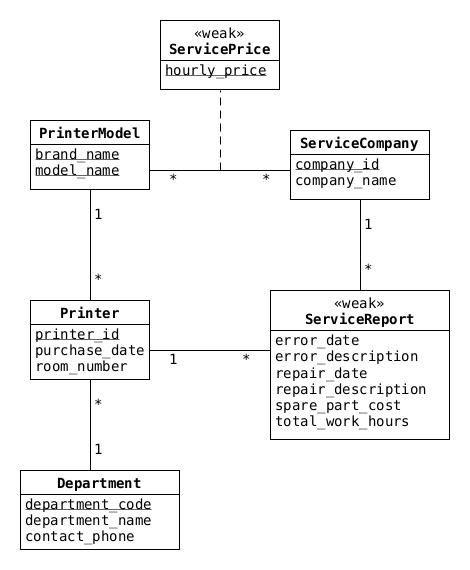
Figure 1: ER model
Man kan tänka sig några relationer till (se kommentarer nedan), men relationerna ovan räcker för att skapa tabeller som ger full poäng:
CREATE TABLE printers ( printer_id TEXT, brand_name TEXT, model_name TEXT, department_code TEXT, purchase_date DATE, room_number TEXT, PRIMARY KEY (printer_id), FOREIGN KEY (brand_name, model_name) REFERENCES printer_models(brand_name, model_name), FOREIGN KEY (department_code) REFERENCES departments(department_code) ); CREATE TABLE printer_models ( brand_name TEXT, model_name TEXT, PRIMARY KEY (brand_name, model_name) ); CREATE TABLE departments ( department_code TEXT, department_name TEXT, contact_phone TEXT, PRIMARY KEY (department_code) ); CREATE TABLE service_companies ( company_id TEXT, company_name TEXT, PRIMARY KEY (company_id) ); CREATE TABLE service_prices ( brand_name TEXT, model_name TEXT, company_id TEXT, hourly_price FLOAT, PRIMARY KEY (brand_name, model_name, company_id), FOREIGN KEY (brand_name, model_name) REFERENCES printer_models(brand_name, model_name), FOREIGN KEY (company_id) REFERENCES service_companies(company_id) ); CREATE TABLE service_reports ( service_report_id TEXT DEFAULT (lower(hex(randomblob(16)))), company_id TEXT, printer_id TEXT, error_date DATE, error_description TEXT, repair_date DATE, repair_description TEXT, spare_part_cost REAL, total_work_hours REAL, PRIMARY KEY (service_report_id), FOREIGN KEY (company_id) REFERENCES service_companies(company_id), FOREIGN KEY (printer_id) REFERENCES printers(printer_id) );
Ovan har vi introducerat en invented key i service_reports, men inte i printer_models – ni fick göra som ni ville i era lösningar (jag hade normalt förmodligen haft en invented key även i printer_models, men ville här visa ett exempel på en sammansatt nyckel).
Några kommentarer till rättningen:
- Oväntat många har separerat ut information om placering och inköpsdatum från skrivar-tabellen till en separat tabell – det är OK (även om tabellerna
printersochprinter_infoär 1-1). - Det går alldeles utmärkt att separera service-rapporten till två delar – en felrapport, och en service-rapport som refererar till fel-rapporten – det är kanske egentligen en snyggare lösning, men inget som vi krävde.
Några har skippat tabellen med skrivarmodeller – det går i princip att köra systemet ändå (eftersom vi inte lagrar mer information om de specifika skrivarmodellerna), det vi missar är:
- möjligheten att få en lite enklare nyckel
- möjligheten att lägga till mer information om skrivarmodellerna, utan att introducera redundans
- det känns rent modellmässing bättre med en separat tabell (det är mest en magkänsla, men jag hoppas att kursen har utvecklat era magar i denna riktning).
Om man vill ha tabeller för skrivarmodellerna kan man argumentera för att även introducera tabeller för skrivartillverkarna (flera av er hade gjort det), och det går naturligtvis alldeles utmärkt!
(1b)
För att hitta de skrivare som aldrig behövt repareras kan vi antingen använda en subquery:
SELECT printer_id, department_name FROM printers JOIN departments USING (department_code) WHERE printer_id NOT IN ( SELECT printer_id FROM service_reports)
… eller en 'outer join':
SELECT printer_id, department_name FROM printers JOIN departments USING (department_code) LEFT JOIN service_reports USING (printer_id) WHERE error_date IS NULL
Båda lösningarna ger full poäng.
Uppgift 2
(2a)
Skriv SQL-kod för att skapa tabellerna employees, areas och area_types – hitta på lämpliga typer för attributen:
CREATE TABLE employees ( employee_id TEXT DEFAULT (lower(hex(randomblob(16)))), name TEXT, hourly_wage REAL, PRIMARY KEY (employee_id) ); CREATE TABLE areas ( area_id TEXT DEFAULT (lower(hex(randomblob(16)))), size INT, area_type TEXT, employee_id TEXT, PRIMARY KEY (area_id), FOREIGN KEY (employee_id) REFERENCES employees(employee_id), FOREIGN KEY (area_type) REFERENCES area_types(area_type) ); CREATE TABLE area_types ( area_type TEXT, work_time REAL, PRIMARY KEY (area_type) );
Ni behövde inte skapa default-nycklar för employees och areas, och det är även helt OK att låta deras nycklar vara INT eller INTEGER.
(2b)
Skriv ut anställningsnummer, namn och timlön för alla städare, i alfabetisk ordning efter namn:
SELECT employee_id, name, hourly_wage FROM employees ORDER BY name;
(2c)
Skriv ut den totala ytan som skall städas, uppdelat efter typ av yta:
SELECT area_type, sum(size) FROM areas GROUP BY area_type;
(2d)
Skriv ut anställningsnummer och namn på de städare som inte har några ytor att städa:
SELECT employee_id, name FROM employees LEFT JOIN areas USING (employee_id) WHERE area_id IS NULL;
… eller, med subquery:
SELECT employee_id, name FROM employees WHERE employee_id NOT IN ( SELECT employee_id FROM areas);
(2e)
Skriv ut anställningsnummer och namn för de städare som har mer än 1000 m2 att städa:
SELECT employee_id, name FROM employees JOIN areas USING (employee_id) GROUP BY employee_id HAVING sum(size) > 1000;
(2f)
Skriv ut den totala tid som behövs för att städa alla ytor:
SELECT sum(size * work_time) FROM areas JOIN area_types USING (area_type);
Uppgift 3
(3a)
Vi får följande funktionella beroenden:
podcast_name -> podcast_producerpodcast_name episode_title -> episode_length episode_datepodcast_name episode_date -> episode_title episode_lengthuser_id -> user_password
Dessa beroenden gav 1 poäng var.
Det var flera som angav beroenden som:
user_id -> podcast_name episode_title episode_date, elleruser_id user_password -> podcast_name episode_title episode_date
men det första av dem skulle innebära att en användare bara kan lyssna på ett enda avsnitt, av en enda podcast, och det andra att man skulle vara tvungen att byta lösenord för varje avsnitt man vill lyssna på.
(3b)
Vi kan börja med att namnge våra funktionella beroenden:
- fd1:
H -> A B - fd2:
E -> F G - fd3:
D E H -> C
D, E och H förekommer inte i något högerled, så de måste alla ingå i alla nycklar.
Om vi beräknar det transitiva höljet av D E H så får vi:
D E H -> D E H A B G F C = A B C D E F G H
vilket visar att det är en nyckel i sig, och eftersom DEH måste vara en del av alla nycklar är det vår enda nyckel (alla andra 'nycklar' skulle vara superkeys, med DEH som en delnyckel).
(3c)
Vi är inte i BCNF eftersom vänsterleden i fd1 och fd2 inte är supernycklar (fd3 är dock i BCNF).
(3d)
Vi har alltså från början:
R(A,B,C,D,E,F,G,H) ------------------ fd: H -> AB, E -> FG, DEH -> C keys: DEH
Vi kan börja med att bryta upp med hjälp av H -> AB, som bryter mot BCNF eftersom H inte är en superkey:
R1(H,A,B) --------- fd: H -> AB keys: H
Denna är i BCNF, eftersom H är en superkey i denna tabell.
Efter att vi tagit bort H -> AB från R har vi kvar:
R2(C,D,E,F,G,H) --------------- fd: E -> FG, DEH -> C keys: DEH
Denna är fortfarande inte i BCNF, eftersom E -> FG har ett vänsterled som inte är en superkey.
Så vi bryter upp R2 med hjälp av E -> FG:
R2a(E,F,G) ---------- fd: E -> FG keys: E
Denna är i BCNF, eftersom E är en superkey, och från R2 återstår:
R2b(C,D,E,H) ------------ fd: DEH -> C keys: DEH
som även den är i BCNF, eftersom DEH är en superkey.
Sammanfattningsvis får vi:
R1(H,A,B)R2a(E,F,G)R2b(C,D,E,H)
Det är även OK att skriva R1 som R1(A,B,H).
(3e)
Det fanns ingen uppgift (3e) på tentan, men i framtiden kommer jag att vara lite tydligare i formuleringen av (3d), och kräva att man tydligt anger varje steg man tar för att bryta upp den ursprungliga relationen, och att man sedan i en uppgift (3e) förklarar hur vi kan återskapa R utan att tappa eller lägga till någonting. Vi kan göra det genom att arbeta oss tillbaka från de tabeller vi härleder, och använda vänsterledet i det beroende vi delar upp på som JOIN-attribut. I just denna uppgift kan vi göra det som:
SELECT A,B,C,D,E,F,G,H FROM R2b JOIN R2a USING (E) JOIN R1 USING (H)
Uppgift 4
I denna uppgift var det flera saker vi ville testa:
att ni kunde skriva triggers, dvs att ni kunde deklarera någonting i stil med
CREATE TRIGGER check_causality BEFORE INSERT ON worklogs
och sedan använda
WHENeller en lämpligt utformadSELECT-CASE-WHEN-sats,- att ni kunde använda syntaxen
NEW.<attribut>för att hämta attribut från den rad som skall läggas in, - att ni kunde göra en
ROLLBACKpå ungefär rätt sätt, och - att ni kunde skriva den övriga SQL-kod som behövs för att lösa de båda uppgifterna.
(4a)
Vi behöver ta reda på vad som är den senaste städningen av den aktuella ytan, enklast är nog att använda max-funktionen:
CREATE TRIGGER check_causality BEFORE INSERT ON worklogs WHEN (SELECT max(cleaned_at) FROM worklogs WHERE area_id = NEW.area_id) > NEW.cleaned_at BEGIN SELECT raise (ROLLBACK, "messing with causality..."); END;
(4b)
Här behöver vi ett sätt att räkna ut arbetskostnaden, vilket kräver att vi JOIN-ar ihop flera tabeller – vi behöver också en korrekt INSERT-sats (enklast är att använda en INSERT-SELECT-sats, som nedan):
DROP TRIGGER IF EXISTS update_payments; CREATE TRIGGER update_payments BEFORE INSERT ON worklogs BEGIN INSERT INTO payments(employee_id, area_id, timestamp, amount) SELECT employee_id, NEW.area_id, NEW.cleaned_at, hourly_wage * work_time * size / 60 FROM areas JOIN employees USING (employee_id) JOIN area_types USING (area_type) WHERE area_id = NEW.area_id; END;
Divisionen med 60 i SELECT-satsen beror på att hourly_wage är en timlön (duh!), men att work_time var mätt i minuter – vi gjorde inga avdrag om ni inte dividerade med 60 (eftersom dokumentationen av work_time fanns i del 1 av tentan).
Uppgift 5
(5a)
En enkel lösning är att introducera en unik id (motsvarande ett personnummer), och att ha mamma och pappa som främmande nycklar i samma tabell (även de är ju personer, med föräldrar). Vi kan på så vis (relativt) enkelt hitta halv- och helsyskon genom att titta på de som delar en eller två föräldrar med oss.
CREATE TABLE persons ( id TEXT, birth_name TEXT, birth_date DATE, mother_id TEXT, father_id TEXT, PRIMARY KEY (id), FOREIGN KEY (mother_id) REFERENCES persons(id), FOREIGN KEY (father_id) REFERENCES persons(id) );
Om man skall vara noga skulle man kanske lyfta ut namnet från denna tabell, eftersom en person kan byta namn, och i en del fall till och med ha flera namn (vi skulle kunna använda en temporal database för det, eftersom olika namn kan ha olika giltighetstid – temporal databases ingår dock för tillfället inte i denna kurs).
(5b)
Det blir en hel del self-joins för att traversera släktträdet, och SQL saknar en enkel mekanism för att loopa, i synnerhet ett godtyckligt antal steg, så det är besvärligt att hitta gemensamma släktingar från tidigare generationer.
(5c)
Neo4j är en grafdatabas, och har algoritmer som kan göra sökningar i grafer (och därmed även träd). Ett (släkt-)träd kan enkelt modelleras med hjälp av en icke-cyklisk graf, och genom att använda Neo4j kan vi använda färdiga graf-algoritmer för att hitta gemensamma förfäder.
Uppgift 6
(6a)
- Serializable: innebär att en transaktion körs helt isolerad från omgivningen, inga andra transaktioner kan ändra data som den aktuella transaktionen arbetar med (åtminstone ser det så ut för transaktionen).
- Read committed: innebär att en transaktion aldrig ser ändringar som andra transaktioner gör, så länge de inte har gjort
COMMIT– men om någon gör en commit medan vår transaktion pågår så kan de data transaktionen arbetar med ändras.
(6b)
Read committed kräver inte att vi blockerar databasen i lika stor utsträckning som serializable, så om vi arbetar med data som inte är jättekänsliga (exempelvis antalet "likes" på ett inlägg), och vill att svarstiderna på vår web-sida skall vara så korta som möjligt, så kan det vara en god idé att använda 'read committed'.
(6c)
Serializable garanterar att databasen befinner sig i ett konsistent tillstånd, och om vi hanterar känsliga data kan vi inte riskera att något går fel bara för att vi skall göra systemet snabbare.