EDAF75 – Project
Background
The programming project is a part of the examination of EDAF75. You must work in groups of two or three students, and all members of the group must contribute to the project in a meaningful way. Unless you notify me (Christian), I'll assume you'll be working in the same groups as in the labs.
Each group will get a supervisor, your supervisors role is to:
- make sure your design is good enough before you start your implementation, and
- make sure your program/documentation meets the requirements once you're finished.
The supervisor is not a part of the group, and is not supposed to help with troubleshooting (the project is an important part of the examination, and you're supposed to show that you can implement your system on your own). You're allowed (even encouraged) to discuss the project with other groups, but you're not allowed to use 'external' help such as ChatGPT, and the solution must be wholly your own (so you're not allowed to copy code from other sources).
The project is divided into several parts (the weeks below are the weeks of "lp vt1", I'll call them 'course weeks'):
Supervisor and repository: In course week 6, you will get an email with some information (such as who will be your supervisor). All your work on the project should be kept in a private git repository on some git service – we haven't yet decided on where it will be (this page will be updated as soon as we know the details). Whatever service we'll use, your supervisor must be given "Developer" access to the repository.
In the first iteration, your repository should contain two files:
- a markdown file,
README.md, which eventually will contain your report, and - a
.png-image,er-model.png, which contains you ER model (see below – the model should be visible on your repository 'landing page').
You can download a template here.
- a markdown file,
Database modeling: Your group should create an ER model for a database which will be used for production and delivery of cookies by the company "Krusty Kookies Sweden AB" (see description below).
The ER model should be drawn as a UML class diagram, with the format used in the following image:
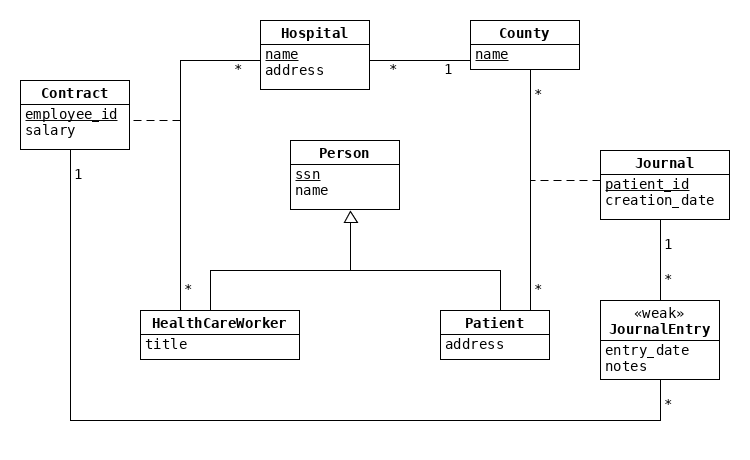
There are plenty of formats for drawing ER-diagrams, such as "Crow's foot", or "Chen", etc., but we willl only accept UML, like in the image above. The image above was created with UMLet, which is a free program running on every platform (if you have no other program which produces diagrams as the one above, use UMLet).
You should bring three copies of your ER-diagram to the design meeting, so the other groups can have a look at it (as you'll have a look at their ER-diagrams).
- Design meeting: In course week 6, we will have a 20-25 minute design meeting which you'll be able to sign up for the week before – at least one group member must participate (there will be some alternative sessions). During this meeting, your group will meet with one or two other groups, and discuss your designs – a supervisor will also attend (not necessarily yours, though), and the purpose of the meeting is to give you an opportunity to discuss design, and come away with a design which makes your implementation straightforward.
Getting the ER-model approved: After the design meeting, we want you to make any necessary updates to your model, and then push it to your repository, so it's visible from the landing page. You should then send an email to your supervisor, so they know you have something to look at – observe that you must send this email even if you've made no updates to the model you had at the meeting.
At this stage there might be a few roundtrips between you and your supervisor (you must notify your supervisor at each turn, so they know they have something to give feedback on), but once your supervisor thinks your model is good enough, they will give you a go-ahead to start implementing the REST service.
- Implementation of a REST API: We want a REST server which communicates with the database – the API for the server will be published some time after the design meeting (see below).
- A written report: The file
README.mdin the root directory of your repository should contain your project report – a detailed description of what the report and repository should contain can be found below.
Important dates
- Start date: Your group can start modeling as soon as you read this, and must have come up with a design before the design meeting in course week 6 – you shouldn't write any code before the design meeting, though (since you need to know that your design is OK before you start coding…).
- Design meeting: There will be two alternative dates for your design meeting, both are in course week 6.
- Deadline: As soon as you think your solution comply with the requirements (see below), you should push the latest version of your project to your repository, and notify your supervisor. If your supervisor wants you to improve your solution, you'll have to keep on pushing new versions until everything is OK. If you haven't pushed an 'approvable' solution by 23:59, April 30, 2024, you'll have to wait for next year's course. Observe that, depending on the supervisor's workload, feedback on your solutions may take a couple of days.
Problem
Krusty Kookies is a bakery which specializes in cookies, and they need a database to keep track of their production and deliveries.
The company sells different kinds of cookies, each with its own recipe – the recipes may change over time, and each year, depending on sales statistics, some recipes are added and some are removed. The following table shows the ingredients needed for producing 100 cookies of each recipe:

The company has a raw materials warehouse in which all ingredients used in their production are stored.
The cookies are baked in lar ge &quantities, and then quickly frozen and packaged in bags with 15 cookies in each bag. The bags are put into boxes, with 10 bags per box. Finally, the boxes are stacked on pallets, where each pallet contains 36 boxes, all containing the same product. This is a sketch depicting the production process, and storage and delivery:
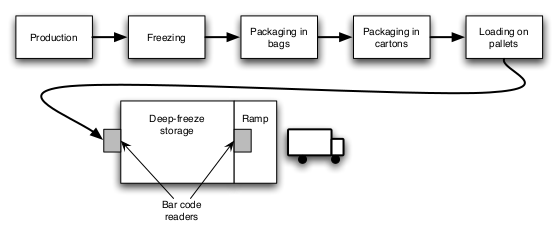
When a pallet is produced and labeled, it is transported to the deep-freeze storeroom – once the pallet reaches the storeroom, the pallet label is read by a bar code reader.
The company only delivers to to wholesale customers, and a typical order looks like "send 10 pallets of Tango cookies, and 6 pallets of Berliners to Kalaskakor AB" – pallets are the unit of all orders (i.e., you can't break up a pallet in an order). Customers place their orders through a web form or by telephone, and all customers must be registered in the database – the current customers are:

On delivery, pallets are transported from the deep-freeze storeroom via a loading ramp to the freezer trucks – each truck loads 60 pallets. The entry to the loading ramp contains a bar code reader which reads the pallet label. Pallets must be loaded in production date order.
When the truck is fully loaded, the driver receives a loading bill containing customer names, addresses, and the number of pallets of each product that is to be delivered to each customer. A transport may contain deliveries intended for different customers.
The company continuously take random samples among the products, and the samples are analyzed in their laboratory. If a sample doesn't meet their quality standards, all pallets containing that product which have been produced during a specific time interval are blocked. A blocked pallet may not be delivered to customers.
A pallet is considered to be produced when the pallet label is read at the entrance to the deep-freeze storage. The pallet number, product name, and date and time of production is registered in the database. The pallet number is unique.
At any time, the company must be able to check how many pallets of a product have been produced during a specific time.
When a pallet is produced, the raw materials storage must be updated, and the company must be able to check the amount in store of each ingredient, and to see when, and how much of, an ingredient was last delivered into storage.
All pallets must be traceable, for instance, the company needs to be able to see all information about a pallet with a given number (the contents of the pallet, the location of the pallet, if the pallet is delivered and in that case to whom, etc.). They must also be able to see which pallets contain a certain product and which pallets have been produced during a certain time interval.
Blocked products are of special interest. The company needs to find out which products are blocked, and also which pallets contain a certain blocked product.
Finally, they must be able to check which pallets have been delivered to a given customer, and the date and time of delivery.
Orders must be registered in the database, and, for production planning purposes, the company must be able to see all orders which are to be delivered during a specific time period.
When the loading bill has been printed, the data regarding delivered pallets must be updated with customer data and date of delivery.
Your task is to implement a REST API which will be used by several frontends running at the company.
Requirements
Program requirements
First of all, your code must follow common coding guidelines (good names, correct indentation, no tabs, etc.) – we will not even look at badly formatted code. If you write in Java, you should also make sure that you use 'try-with-resources' when you create your statements (see notes from lecture 5).
The REST API we want you to implement is described here.
Repository requirements
Your repository must contain:
A diagram (in .png-format) which shows your ER-model using a UML class diagram (not hand drawn) – the file should be named
er-model.png.We are going to be very fuzzy about this diagram, it must be absolutely correct (proper UML-notation, primary keys marked, no foreign keys, all cardinalities written out, etc.). Also observe that Crow's foot/Martin, Chen, or any other format is not allowed.
- A file
create-schema.sqlwith the SQL statements needed to create the tables your ER-model would require. A markdown file
README.md, which contains your report. The report should show:- The UML diagram of your ER-model (see above – for help on how to import images into markdown files, see here).
- A link to your sql-script (see here for help on how to link to files within your repository).
- Comments on how to setup your server (i.e., how to compile/run the program).
If it is properly written, you should be able to see your report at the bottom of your project's "Overview" page.
- The source tree for your REST service (only source code, make sure to add
.classto your.gitignorefile if you write Java code).
You can download a template report (i.e., an zip-archive with a README.md file which contains most of the things you need to get a proper report) – just unpack the zip-archive, and put the file README.md in the top directory of your repository (if you also copy the image er-model.png, you'll see a placeholder for your own ER-model).
Peer review meeting discussion points
Below are some things to discuss when you review each others' designs during the peer review meeting – make sure you think this through for your own design before the meeting.
Overview of the design
Start by looking at your own E/R diagram, check if it complies with the UML standard for class diagrams:
- Are entity sets correctly formatted (i.e., do the boxes look OK, are the entity set name and the attributes in different compartments, are the first letter of the entity set names capitalized, and are the names in singular form)? Compare to the format of the ER-diagram at the top of this page.
- Are keys correctly marked (no matter if they're the correct keys, we'll return to that)?
- Are relationships (associations) correctly drawn, and do they all have their cardinalities marked?
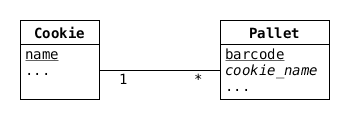
Below is an incorrect E/R diagram, what's wrong with it?
When you look at the other groups' E/R diagrams, compare their design with your own group's design:
- What differs from your design?
- Are all entity sets relevant?
- Are all attributes in the entity sets relevant?
- Is anything missing?
- Are all associations relevant?
- Are the cardinalities correct?
- Are the keys correct?
- Which keys are natural/invented? Is there any reason to substitute a natural key for an invented key, or vice versa?
Recipes
- Is it easy to add a new recipe, and is it easy to change a recipe?
- When you add a new recipe you might need to add a new ingredient, it should be possible to do so using operations, without modifying the structure of the database. Using a wide table with one column for each possible ingredient is a bad design, since adding a new ingredient will require modification of the database structure.
Ingredients
- There is a requirement that the date and size of the last delivery for each ingredient should be stored – does your design meet this requirement?
Order-Delivery
- Does the design distinguish between orders and deliveries?
- When is a pallet bound to an order?
- Below there are some use cases to check this part of the design – for each use case, describe the database operations.
- Two pallets of ”Nut Rings” are produced, make sure the raw materials inventory is updated. How do we handle running short of ingredients while producing a pallet?
- On March 4th, ”Café sju sorters kakor” orders two pallets of ”Amneris” and three pallets of ”Nut rings” to be delivered on March 25th. Make sure that different kinds of cookies in an order can be ordered in different quantities.
- The deep-freeze storage is empty. On March 4th, ”Café sju sorters kakor” orders two pallets of ”Amneris” to be delivered on March 25th. The cookies are baked on March 20th, and delivered on March 25th. Make sure you can enter orders even if the cookies are not in stock.
- There are two pallets of ”Amneris” in the deep-freeze room. On March 4th, ”Café sju sorters kakor” orders two pallets of ”Amneris” to be delivered on March 25th. On March 6th, ”Lilla Caféet” orders one pallet of ”Amneris” to be delivered on March 10th. On March 9th, two pallets of ”Amneris” are baked. Which pallet is delivered to ”Lilla Caféet”? The oldest pallet must be delivered first. The use case checks so a pallet is not allocated to an order before delivery.
- The deep-freeze storage is empty. On March 4th ”Café sju sorters kakor” orders two pallets of ”Amneris” and three pallets of ”Nut Rings” to be delivered on March 25th. The cookies are baked on March 25th, but one pallet of ”Nut rings” is blocked due to poor quality. There is no time to bake new cookies, so two pallets of ”Amneris” and one pallet of ”Nut rings” are delivered. How is this recorded in the database? Can you from the database determine that only part of the order was delivered?. NOTE, you do not need to handle this case, but with a good design, it takes no extra effort to do it.