Session 9 – notes
Here are some notes for the Monday lecture in week 5. I spent most of the time going through the slides and implementing some triggers – you can see the slides here, and you can read more about triggers in SQLite here.
Using table constraints to keep table data valid
The first example we looked at was:
Example: Make sure no one enters an invalid gpa for a student in the students table.
Our initial definition for the students table was:
CREATE TABLE students( s_id INTEGER, s_name TEXT, gpa REAL, PRIMARY KEY (s_id) );
The SQLite3 syntax diagram for CREATE TABLE shows that we can add constraints to our columns:
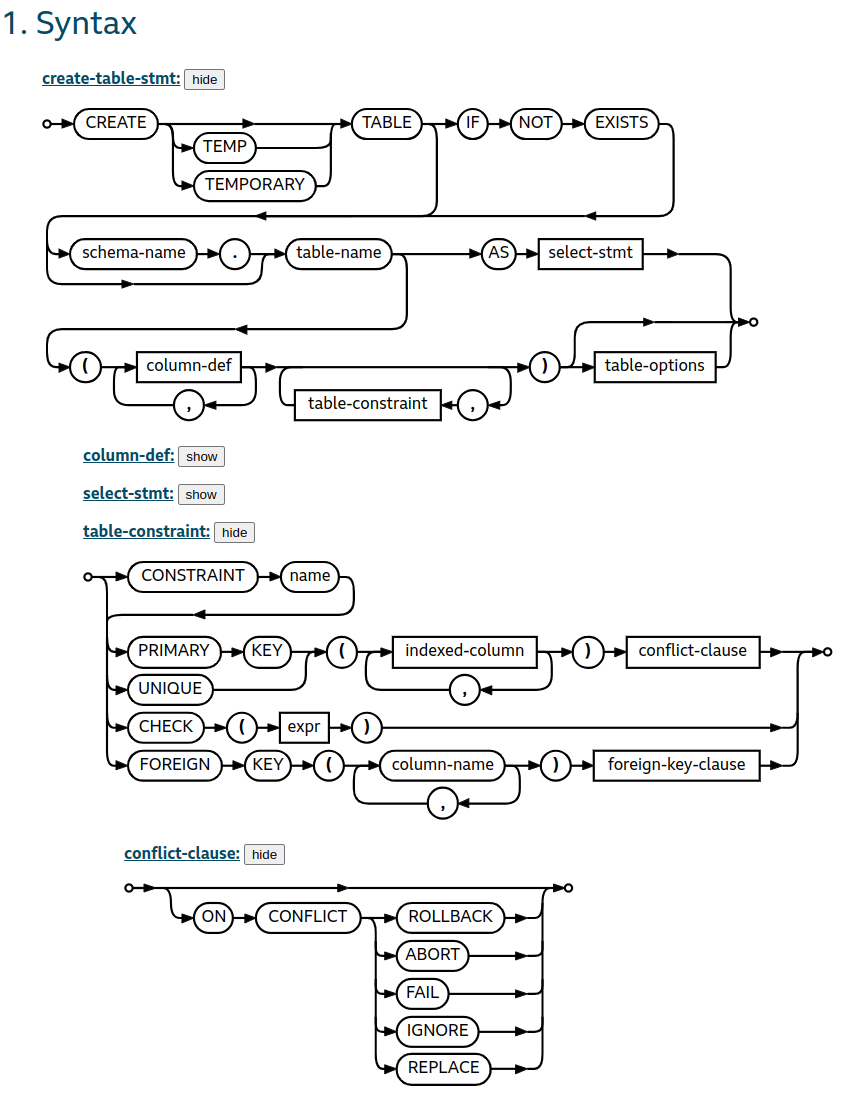
(The diagram says that CHECK can't be followed by a conflict-clause, but that's what we did anyways – I think this is just an omission in the diagram.)
So, we added a constraint, calling it valid_gpa:
CREATE TABLE students(
s_id INTEGER,
s_name TEXT,
gpa REAL DEFAULT (1.0),
PRIMARY KEY (s_id),
CONSTRAINT valid_gpa
CHECK (gpa BETWEEN 1.0 AND 4.0)
ON CONFLICT ROLLBACK
);
I created a database using our new schema and our old data (the $ is just the CLI prompt, it doesn't belong to the command):
$ sqlite3 colleges.sqlite < schema.sql $ sqlite3 colleges.sqlite < data.sql $ sqlite3 colleges.sqlite SQLite version 3.44.2 2023-11-24 11:41:44 Enter ".help" for usage hints. sqlite> .mode column
We first looked at the current data:
SELECT * FROM students;
s_id s_name gpa ---- ------ --- 123 Amy 3.9 234 Bob 3.6 345 Craig 3.5 456 Doris 3.9 543 Craig 3.4 567 Edward 2.9 654 Amy 3.9 678 Fay 3.8 765 Jay 2.9 789 Gary 3.4 876 Irene 3.9 987 Helen 3.7
and then tried to insert an invalid gpa:
sqlite>
INSERT
INTO students(s_name, gpa)
VALUES ('Bob', 0.6);
Runtime error: CHECK constraint failed: valid_gpa (19)
When we tried to update to an illegal gpa we were stopped by the same constraint:
sqlite> UPDATE students SET gpa = 4.1 WHERE s_id = 123; Runtime error: CHECK constraint failed: valid_gpa (19)
So, our constraint works, and relieves us from keeping track of the grades 'by hand' (the database takes care of it by itself).
We then looked at a similar looking problem:
Exercise: Make sure no one lowers the gpa of a student in the students table.
To do this, we need two values: the new value of the gpa, but also the previous value – the problem is that when we define a constraint as we did above, we only have access to the value we want to save, not the previous value.
So we started looking at triggers, and went through some slides (you can also look through the SQLite documentation for triggers).
Using triggers to keep table data valid
When we write a trigger for an update, we'll have access to two 'rows':
OLD: The row which we're about to update – in this case we can check the previous value ofgpausingOLD.gpaNEW: The row as we want it to look after the update – in this case we can check the newgpausingNEW.gpa.
If the new gpa is less than the previous gpa, we should rollback the transaction:
CREATE TRIGGER dont_lower_grades BEFORE UPDATE ON students WHEN OLD.gpa > NEW.gpa BEGIN SELECT RAISE (ROLLBACK, 'Thou shalt not lower grades!'); END;
(I first omitted the ',' after ROLLBACK, and got a messy error message – my only excuse is that I wrote some scheme code this weekend).
In this case we could have used either BEFORE UPDATE or AFTER UPDATE, the results would have been the same.
We can solve this without using the WHEN condition, instead using a SELECT CASE WHEN statement inside the BEGIN-END part of the trigger, but it's probably harder to understand (you can interpret this as if we did a WHEN TRUE, and then had the logic for when to roll back in the SELECT CASE WHEN statement):
CREATE TRIGGER dont_lower_grades
BEFORE UPDATE ON students
BEGIN
SELECT CASE OLD.gpa > NEW.gpa
WHEN TRUE THEN
RAISE (ROLLBACK, 'Thou shalt not lower grades!')
END;
END;
We then discussed how to make sure that students don't apply for to many majors at any given college.
We started with some scaffolding – I said that our trigger would end up looking something like:
DROP TRIGGER IF EXISTS limit_applications; CREATE TRIGGER limit_applications BEFORE INSERT ON applications WHEN -- todo BEGIN SELECT RAISE (ROLLBACK, 'Too many applications to same college'); END;
Here we want to check that the student in the new application (called NEW) doesn't have more than 2 applications to the given college already, and we came up with the following query to see the current value:
SELECT count()
FROM applications
WHERE s_id = NEW.s_id
AND c_name = NEW.c_name
and in the trigger, we want to compare this value with 2 (if it's 2 or bigger we want a ROLLBACK):
DROP TRIGGER IF EXISTS limit_applications;
CREATE TRIGGER limit_applications
BEFORE INSERT ON applications
WHEN
(SELECT count()
FROM applications
WHERE s_id = NEW.s_id
AND c_name = NEW.c_name) >= 2
BEGIN
SELECT RAISE (ROLLBACK, 'Too many applications to same college');
END;
Here there is a difference between using BEFORE INSERT and AFTER INSERT – above we checked the number of applications before we made the insertion, if we had used AFTER INSERT, we'd have to write:
DROP TRIGGER IF EXISTS limit_applications;
CREATE TRIGGER limit_applications
AFTER INSERT ON applications
WHEN
(SELECT count()
FROM applications
WHERE s_id = NEW.s_id
AND c_name = NEW.c_name) >= 3
BEGIN
SELECT RAISE (ROLLBACK, 'Too many applications to same college');
END;
since the new value would need to be counted.
When we try our limit_applications trigger, and add it to our database schema, we get the following output:
$ sqlite3 colleges.sqlite < schema.sql $ sqlite3 colleges.sqlite < college-data-as-single-inserts.sql Runtime error near line 27: Too many applications to same college (19)
If we look at our applications table, it's empty.
What happens is that Craig (with s_id 345) applies to Cornell three times in our original database, and that makes the trigger rollback the INSERT statement into applications (see the file college-data-as-single-inserts.sql). This INSERT statement was written as:
INSERT
INTO applications(s_id, c_name, major, decision)
VALUES (123, 'Stanford', 'CS', 'Y'),
(123, 'Stanford', 'EE', 'N'),
(123, 'Berkeley', 'CS', 'Y'),
(123, 'Cornell', 'EE', 'Y'),
(234, 'Berkeley', 'biology', 'N'),
(345, 'MIT', 'bioengineering', 'Y'),
(345, 'Cornell', 'bioengineering', 'N'),
(345, 'Cornell', 'CS', 'Y'),
(345, 'Cornell', 'EE', 'N'),
(678, 'Stanford', 'history', 'Y'),
(987, 'Stanford', 'CS', 'Y'),
(987, 'Berkeley', 'CS', 'Y'),
(876, 'Stanford', 'CS', 'N'),
(876, 'MIT', 'biology', 'Y'),
(876, 'MIT', 'marine biology', 'N'),
(765, 'Stanford', 'history', 'Y'),
(765, 'Cornell', 'history', 'N'),
(765, 'Cornell', 'psychology', 'Y'),
(543, 'MIT', 'CS', 'N');
and it's just one SQL statement, so if any insertion is rolled back, all of them are.
If we instead had written (as in college-data-as-single-inserts.sql)
INSERT INTO applications(s_id, c_name, major, decision) VALUES (123, 'Stanford', 'CS', 'Y'); INSERT INTO applications(s_id, c_name, major, decision) VALUES (123, 'Stanford', 'EE', 'N'); INSERT INTO applications(s_id, c_name, major, decision) VALUES (123, 'Berkeley', 'CS', 'Y'); ...
each insertion is its own statement, and since the SQLite CLI has autocommit as default, only those individual insertions which would 'trigger our trigger' would be rolled back.
If we change our trigger so we accept three applications to each college (i.e., we substitute the 2 above for 3), and then run:
SELECT s_id, s_name, c_name, count(), group_concat(major)
FROM applications
JOIN students USING (s_id)
GROUP BY s_id, c_name
ORDER BY count() DESC;
we get:
s_id s_name c_name count() group_concat(major) ---- ------ -------- ------- ---------------------- 345 Craig Cornell 3 CS,EE,bioengineering 123 Amy Stanford 2 CS,EE 765 Jay Cornell 2 history,psychology 876 Irene MIT 2 biology,marine biology 123 Amy Berkeley 1 CS 123 Amy Cornell 1 EE 234 Bob Berkeley 1 biology 345 Craig MIT 1 bioengineering 543 Craig MIT 1 CS 678 Fay Stanford 1 history 765 Jay Stanford 1 history 876 Irene Stanford 1 CS 987 Helen Berkeley 1 CS 987 Helen Stanford 1 CS
If we now let Amy with s_id 123 apply one more time to Stanford, it's OK:
INSERT INTO applications(s_id, c_name, major) VALUES (123, 'Stanford', 'biology');
but the next application:
INSERT INTO applications(s_id, c_name, major) VALUES (123, 'Stanford', 'history');
will be rejected (as it would be Amy's fourth application to Stanford).
Add some logging
The next thing we want to do is to get some kind of 'log' of all updates of the students' grades.
Here we start by defining a new table, which has four columns:
- the time for the update (as a
DATETIME), and a description of the update (student id, previous gpa, and new gpa):
DROP TABLE IF EXISTS updated_gpas; CREATE TABLE updated_gpas ( update_time DATETIME DEFAULT (DATETIME('now')), s_id INT, previous_gpa REAL, updated_gpa REAL );
We have no primary key in this table, it's just meant to be a log of events (there is no need to make sure the rows are unique).
Now we can insert a trigger for updates of gpa in students – this time I look at updates of a specific attribut (gpa) in a specific table (students):
DROP TRIGGER IF EXISTS log_update_students_gpas; CREATE TRIGGER log_update_students_gpas BEFORE UPDATE OF gpa ON students BEGIN INSERT INTO updated_gpas(s_id, previous_gpa, updated_gpa) VALUES (OLD.s_id, OLD.gpa, NEW.gpa); END;
Every update we make will generate a row in our updated_gpas table, with a timestamp and description of the change
If we run:
UPDATE students SET gpa = gpa * 1.1;
we would violate our valid_gpa constraint, and the whole update statement would be rolled back – this means that our updated_gpas will be empty (observe that it's only one statement, and that the SQLite CLI has autocommit turned on, but that makes no difference if the only statement we run initiates a rollback).
If we make sure not to update to invalid grades, e.g.:
UPDATE students SET gpa = min(4.0, gpa * 1.1);
our update would be committed, and we can see our log:
SELECT * FROM updated_gpas
This produces something like:
sqlite> SELECT * FROM updated_gpas; update_time s_id previous_gpa updated_gpa ------------------- ---- ------------ ----------- 2025-02-17 14:44:24 123 3.9 4.0 2025-02-17 14:44:24 234 3.6 3.96 2025-02-17 14:44:24 345 3.5 3.85 2025-02-17 14:44:24 456 3.9 4.0 2025-02-17 14:44:24 543 3.4 3.74 2025-02-17 14:44:24 567 2.9 3.19 2025-02-17 14:44:24 654 3.9 4.0 2025-02-17 14:44:24 678 3.8 4.0 2025-02-17 14:44:24 765 2.9 3.19 2025-02-17 14:44:24 789 3.4 3.74 2025-02-17 14:44:24 876 3.9 4.0 2025-02-17 14:44:24 987 3.7 4.0
Using triggers from Python code
One (of many) great things with triggers is that they let us move many things from our 'external' code into the database, where we can also reuse it. In lecture 6 we implemented a simple REST service for our student database, and in it we had an endpoint which let the users add a new student:
@post('/students')
def post_student():
student = request.json
c = db.cursor()
try:
c.execute(
"""
INSERT
INTO students(s_id, s_name, gpa)
VALUES (?,?,?)
RETURNING s_id
""",
[student['id'], student['name'], student['gpa']]
)
found = c.fetchone()
if not found:
response.status = 400
return "Illegal..."
else:
db.commit() # This is very important!
response.status = 201
s_id, = found
return f"http://localhost:{PORT}/{s_id}"
except sqlite3.IntegrityError:
response.status = 409
return "Student id already in use"
Since s_id is a primary key, we're not allowed to have duplicates, and we could have checked that the new student's id wasn't already in the database before we added a new row to students (we could also have let the database generate a unique id by just omitting s_id in the INSERT statement, but that's beside the point for this example).
But since the database would give us an 'integrity error' if we tried to insert a duplicate password, we can try to insert the new student without first checking the id, and then handle any error sent back from the database in case it was a duplicate.
Observe that we need to commit the insertion if we get no errors (the SQLite CLI is in autocommit mode by default, but the pysqlite library isn't, and we must commit everytime we change the database in any way).
The duplicate key error was generated automatically by the database, and the same now goes for the trigger which checks that no student applies for too many majors at one college. To have the database limit the number of applications at a given college, the only things we need to change from lecture 6 is:
- we must add our trigger to the database (in the
schema.sqlfile), and restart the database, so it uses the trigger, and - we must check the integrity error returned from the database.
A very simple way to do this is to just return the message sent from the database (in this case we're still setting the response code to 409) – observe that the only change from above is the last line:
@post('/students')
def post_student():
student = request.json
c = db.cursor()
try:
c.execute(
"""
INSERT
INTO students(s_id, s_name, gpa)
VALUES (?,?,?)
RETURNING s_id
""",
[student['id'], student['name'], student['gpa']]
)
found = c.fetchone()
if not found:
response.status = 400
return "Illegal..."
else:
db.commit() # This is still very important!
response.status = 201
s_id, = found
return f"http://localhost:{PORT}/{s_id}"
except sqlite3.IntegrityError as e:
response.status = 409
return str(e)
The message in the IntegrityError here (e) will be the text we used in our SELECT RAISE (ROLLBACK, 'Too many applications to same college') statement above.
We could also have our Python code have a look at the returned message, in case we wanted different response codes for different integrity errors.
In lab 3 we can do something similar to make sure we don't sell more tickets than we have – by using a trigger which checks that there are available tickets when we try to sell them, we wouldn't have to check it in advance, in our Python code (our Python code could just try to book another ticket, and then handle any error from the database in a try-except statement, as above).
Make sure no one applies for an unknown major@college
During an earlier lecture we talked about keeping track of what combinations of college and major are available, in this exercise we'll assume that exactly those who people have sought are available.
So our trigger could check if there are any earlier applications for the c_name and major in NEW:
DROP TRIGGER IF EXISTS only_known_programs;
CREATE TRIGGER only_known_programs
BEFORE INSERT ON applications
WHEN
NOT EXISTS (
SELECT s_id
FROM applications
WHERE c_name = NEW.c_name
AND major = NEW.major)
BEGIN
SELECT RAISE (ROLLBACK, 'unknown program');
END;
Exercise: This solution is very awkward, and it suffers from 'insertion anomalies' (we have no place to save information about which college-major combos are available until someone applies for them, and to make things even worse, the trigger would stop us from inserting them anyways…). So, try to come up with a better design to avoid this problem – it's a bonus if you at the same time find a way to keep track of how many students should be allowed into each college-major offering. You'll need more tables! Feel free to ask me about your solution during QA sessions, or during lecture breaks.