EDAF75: Database technology
Session 6 – notes
Here are some resources for lecture 6 (the Thursday lecture in course week 3). I spent most of the time going through the slides and implementing parts of a simple REST server in Python – you can see the slides here.
I started by trying to illustrate how we can use a database server from various kinds of clients (notebooks, GUIs like sqlitebrowser, the sqlite3 command line interpreter, and Python programs like the one we wrote last time):
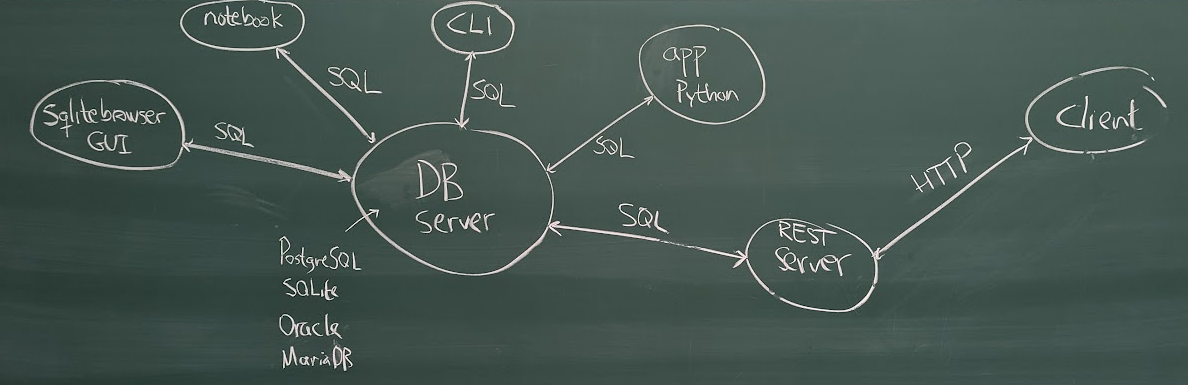
This time we added a program which itself will be a server (we'll call it a REST server, although it may be more accurate to call it a 'JSON over HTTP' server).
I waved my hands a bit, trying to explain how we could use HTTP (the same protocol which web browsers talk to their websites with) to send requests for various resources, and use JSON to specify data (hence 'JSON over HTTP').
The slides illustrate some details of the HTTP protocol, not because it's important for databases per se, but because this is a technique which is often used in conjunction with databases.
The major point of having our REST service is that it's a front end to our database, and we can use it to shield the database from the outside world. REST services are typically used from web apps, who call the service to get data to present in the browser.
During the course you'll have to implement two REST services of your own, one for lab 3, and one for the project – in both cases you can use either Python/Bottle or Java/SparkJava.
The text below describes:
- a simple Python implementation of a server using the Bottle library, and
- a
gradleproject with a server written in Java, using the SparkJava library.
Knowing the basics of JDBC, i.e., the Java standard classes used for communicating with an SQL database (such as Connection, Statement, PreparedStatement, ResultSet, etc.) is part of the course, but the details of writing a REST service in Java using JavaSpark is not.
So, if you decide to use Python for lab 3 and the project, you can skip the rather lengthy description of the Java server below. And similarily, if you chose to write lab 3 and the project in Java, you don't need to read about the Python server shown below.
More about REST
You don't need to learn how to design REST apis in this course, but there's a good website describing principles for designing a REST API – it's way beyond the scope of this course, but may give you some perspective.
Python/Bottle version (not required, but highly recommended!)
Those of you who know Python, or want to learn it so you can use it in this course, can use a great library called Bottle (there are many others, some of them quite a bit more advanced, but for the purpose of this course, Bottle will do nicely). So I started to implement some endpoints of a REST service in Python.
There are several different ways to install Python and Bottle on your own computer, I've started to use uv, but you can easily google your way to a number of setups. I'll leave it to you how to handle the installation.
To create a directory for the lecture, and set up a Bottle service in it, I wrote (in the same kind of CLI we saw last time):
$ mkdir lect-06 && cd lect-06 $ uv init $ uv add bottle
I also copied the database we used in lecture 2, and extracted the tables for college applications from it (as we did last time):
$ cp ../lect-02/lect02.sqlite . $ sqlite3 lect02.sqlite ".dump students colleges applications" > create-college-data.sql $ sqlite3 colleges.sqlite < create-college-data.sql
I now created a file app.py using my text editor, and we began with the simlest possible service, which just answers GET calls to the endpoint /ping:
from bottle import get, post, request, response, run
HOST = 'localhost'
PORT = 4567
@get('/ping')
def get_ping():
response.status = 200
return 'pong'
run(host=HOST, port=PORT)
To run this, I used uv:
$ uv run app.py
With a regular Python installation I could've started it with:
$ python app.py
For this to work, the Bottle library must be installed (either globally, or locally).
The service runs on localhost, which is our own computer, and listens at port 4567 – we tried to make a call from a client called curl:
$ curl -X GET http://localhost:4567/ping pong
We then implemented some endpoints, such as:
GET /students, which returns all studentsGET /students/<s_id>, which returns the student with a given idGET /students, with any of two query parameters (nameandminGpa)POST /students, which adds a new student
You'll find our implementations of these endpoints below.
Looking for a specific student resource
During the lecture, I first implemented the regular "/students"-endpoint, using the function get_students():
from bottle import get, post, run, request, response
import sqlite3
PORT = 4567
db = sqlite3.connect('colleges.sqlite')
@get('/students')
def get_students():
c = db.cursor()
c.execute(
"""
SELECT s_id, s_name, gpa
FROM students
"""
)
response.status = 200
found = [{"id": id,
"name": name,
"gpa": grade} for id, name, grade in c]
return {"data": found}
run(host='localhost', port=PORT)
I tried to explain how the list comprehension where we picked values from our query result works, there is an attempt at another explanation near the bottom of this page.
The @get('/students') thingy just before the definition of get_students is a decorator, which Bottle uses to tie GET requests for the endpoint "/students" to the function get_students – it also ensures that Bottle transforms the return value of the function into something appropriate, typically a JSON object.
One thing which is a bit surprising is that Bottle doesn't handle lists as return values, but REST services (or JSON over HTTP) typically wrap their results inside an object with the field "data", so that's what the return statement does.
If we had been dead set on returning just a JSON list, we could have done so using Python's standard JSON package (import json and then json.dumps(found)), but the wrapped return value above is the prefered way to do it.
Looking for a specific student resource
Looking for a specific student using their s_id, we add the id to the endpoint URL (I showed you this during the lecture), and Bottle will extract id it into an argument to the decorated function:
@get('/students/<s_id>')
def get_student(s_id):
c = db.cursor()
c.execute(
"""
SELECT s_id, s_name, gpa
FROM students
WHERE s_id = ?
""",
[s_id]
)
found = [{"id": id,
"name": name,
"gpa": grade} for id, name, grade in c]
if len(found) == 0:
response.status = 404
else:
response.status = 200
return {"data": found}
We can now find information about just one student, but we return a list (which is nice, since we only need to return an empty list in case there is no student with the given id).
$ curl -X GET http://localhost:4567/students/123
{"data": [{"id": 123, "name": "Amy", "gpa": 3.9, "sizeHS": 1000}]}%
$ curl -X GET http://localhost:4567/students/628
{"data": []}%
We also tried this endpoint inside a tool called "insomnia" (the version I used is free), but there are many alternatives.
Using query strings to find specific values
Sometimes we want to have a way to filter out specific values, if we want just all student with the name "Amy", we want to be able to use the call:
$ curl -X GET http://localhost:4567/students?name=Amy
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
}
]
}
The exact format of the query string depends on where we write it, when I write the call above in my terminal window (Alacritty running on Arch Linux), it adds a backslash before the question mark, and before the equal sign, so it looks like:
$ curl -X GET http://localhost:4567/students\?name\=Amy
but YMMV (depending on what operating system you're on, and what command line client or tool you use).
BTW, the output of the command was actually much 'messier' (everything on one line), but I piped it through the program jq, which makes it look much nicer (as above).
As an example we can also add a way to find only student with a minimum gpa (now I've copied the call verbatim from my terminal window):
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9 | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
},
{
"id": 456,
"name": "Doris",
"gpa": 3.9,
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
},
{
"id": 876,
"name": "Irene",
"gpa": 3.9,
}
]
}
We can also combine the two queries:
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9\&name\=Amy | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
}
]
}
The query parameters are sent as a part of the URL, and many of the symbols we might want to use in our queries, such as spaces, commas and periods, aren't allowed in a URL. Fortunately we can use URL encoding (also known as Percent-encoding), which is a standardized way of translating a string with 'illegal' characters into a safe string, and back again. As an example, using URL encoding we can translate the string
to be, or not to be
into
to%20be%2C%20or%20not%20to%20be
In Python we can import the quote and unquote functions from urllib.parse:
from urllib.parse import quote, unquote
which gives us quote to translate from regular text into 'safe' strings, and unquote to translate back to regular text again (I had some serious problems writing 'unquote', it's one of the very, very few words which are actually more difficult to write using the Dvorak layout than using QWERTY).
To add query parameters to our requests, we write an updated version of the getStudents method we saw above – now we have to check which query parameters are in request (for requests without parameters, it's going to work as before). One way to do this is to first create a query which is amenable to the addition of zero or more extra conditions.
So instead of
SELECT s_id, s_name, gpa, size_hs FROM students
I added the seemingly nonsensical WHERE TRUE:
SELECT s_id, s_name, gpa, size_hs FROM students WHERE TRUE
This is a very pragmatic trick, and the point of it is that we now can add zero or more lines with additional conditions:
SELECT s_id, s_name, gpa, size_hs
FROM students
WHERE TRUE
AND s_name = ?
AND gpa > ?
We can ask request for potential query parameters by just testing if they're defined – the expression
request.query.name
contains the value of the query parameter name, if it's set, or None if it's not set.
This is what we ended up with:
@get('/students')
def get_students():
query = """
SELECT s_id, s_name, gpa
FROM students
WHERE TRUE
"""
params = []
if request.query.name:
query += "AND s_name = ?"
params.append(unquote(request.query.name))
if request.query.minGpa:
query += "AND gpa >= ?"
params.append(request.query.minGpa)
c = db.cursor()
c.execute(
query,
params
)
response.status = 200
found = [{"id": id,
"name": name,
"gpa": grade} for id, name, grade in c]
return {"data": found}
To use this, the caller must URL-encode her query parameters – for simple strings as above, it will make no difference:
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9\&name\=Amy
but to look for "Obi wan", the encoding looks a bit different:
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9\&name\=Obi%20wan
When I try this (and pipe though jq, a JSON formatter), I get:
curl -X GET http://localhost:4567/students\?name\=Amy | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHS": 1000
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
"sizeHS": 1000
},
{
"id": 988,
"name": "Amy",
"gpa": 3.2,
"sizeHS": 400
}
]
}
If we try with two query strings at the same time, we get:
$ curl -X GET http://localhost:4567/students\?name\=Amy\&minGpa\=3.6 | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHS": 1000
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
"sizeHS": 1000
}
]
}
Posting data to the REST service
One of the many nice features of Bottle is that it provides a value request.json, which contains any JSON object in the request body, and serves it as a dictionary.
This makes it remarkably easy to implement POST to our endpoints, this is all it takes to add a new student:
@post('/students')
def post_student():
student = request.json
c = db.cursor()
try:
c.execute(
"""
INSERT
INTO students(s_id, s_name, gpa)
VALUES (?,?,?)
RETURNING s_id
""",
[student['id'], student['name'], student['gpa']]
)
found = c.fetchone()
if not found:
response.status = 400
return "Illegal..."
else:
db.commit()
response.status = 201
s_id, = found
return f"http://localhost:{PORT}/{s_id}"
except sqlite3.IntegrityError:
response.status = 409
return "Student id already in use"
Observe that we have to call db.commit() after we have updated our table – it has to do with transactions, which we'll talk about in a couple of weeks.
Here we use a relatively new SQLite construct:
INSERT INTO students(s_name, gpa, size_hs) VALUES (?, ?, ?) RETURNING s_id
This only works if our table has an auto generated primary key, and our students table have just such a key:
DROP TABLE IF EXISTS students; CREATE TABLE students ( s_id INTEGER, s_name TEXT, gpa REAL, PRIMARY KEY (s_id) );
A primary key which is declared as an INTEGER will get start values automatically (normally just an increasing sequence).
Another way to generate random keys is:
DROP TABLE IF EXISTS students; CREATE TABLE students ( s_id TEXT DEFAULT (lower(hex(randomblob(16)))), s_name TEXT, gpa REAL, size_hs INT, PRIMARY KEY (s_id) );
These keys can also be returned using an INSERT-RETURNING statement.
Adding hirerarchical endpoints
We can also provide 'sub-endpoints', such as /students/<s_id>/applications, which gives all applications for a given student (I didn't have time to do this during the lecture, but there isn't really anything new in this endpoint):
@get('/students/<s_id>/applications')
def get_student_applications(s_id):
c = db.cursor()
c.execute(
"""
SELECT s_id, c_name, major, decision
FROM applications
JOIN students
USING (s_id)
WHERE s_id = ?
""",
[s_id]
)
found = [{"id": s_id,
"college": c_name,
"major": major,
"decision": decision}
for s_id, c_name, major, decision in c]
response.status = 200
return {"data": found}
We have to make sure we have a proper database file (colleges.sqlite), and then start the server with:
$ uv run app.py
(or just python app.py if you use a regular Python environment).
If there's anything in this program you don't understand, feel free to come to the QA sessions and ask!
In case you get interested in doing some more work with REST services in Python on your own, you should have a look at FastAPI, which is insanely good. It may take some work to get it up and running (you should probably use uv), and some students who used it for lab3 and the project in previous years had problems with it which weren't database related, so we'll not use it in the course this year.
A Java server
If you decide to use Python for lab 3 and the project, you don't have to read this section.
You can download a gradle project with the code below here.
To run the this server, you must first unpack the archive, step into the unpacked directory, make sure there's a database (colleges.sqlite) in the app directory, and then start the server with the command:
$ ./gradlew run
or, if you run Windows:
$ gradlew run
When we start our server, we'll get the message:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder" SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
This is nothing to worry about – line two says that we'll not get any specially configured logging, but the program will still run (and given all the recent fuzz about log4j, we may be better of not having it loaded :-)).
Once the program (i.e., the REST server) is up and running, we can send requests to it – we'll see how to do that below.
The Java server we wrote is based on the SparkJava framework (developed by an LTH alumnus!) – you can find its official web site here and javadoc documentation here.
SparkJava uses 4567 as its default port number, but we can use any port number from 1024 up to 65535 (lower port numbers are reserved for other services) – we chose 4567.
I've created the distributed project with:
$ gradle init
and added the same Database template we used for the previous lecture in our app/src/main/java/demo folder. We also updated the generated App class to:
package demo;
import static spark.Spark.*;
public class App {
public static void main(String[] args) {
new App().run();
}
void run() {
port(4567);
get("/hello", (req, res) -> "hello, world!");
}
}
To compile and run this, gradle needs to know where it can find sparkjava, so we added a dependency in app/build.gradle (unfortunately, the docs for sparkjava says we should use this a compile dependency, but it really should be an implementation dependency):
...
dependencies {
... as before ...
implementation "com.sparkjava:spark-core:2.9.4"
... as before ...
}
...
The Spark part of run() above is
port(4567);
which tells Spark to listen to port 4567, and
get("/hello", (req, res) -> "hello, world!");
which tells Spark that GET requests to the resource /hello should be handled by the lambda expression:
(req, res) -> "hello, world!"
which, obviously, just returns the string "hello, world!".
Getting all students, version 1
Just as we did last time, we'll put all database related code in our Database class, and the first thing we'll try is to add GET on /students (which should return all students) – we can do it by adding this line in the run() method in App:
get("/students", (req, res) -> db.getStudents(req, res));
This means we have to implement the following method in our Database class:
class Database {
// ... as in the previous lecture ...
public String getStudents(Request req, Response res) {
// ...
}
}
The return value of this method is a String with a JSON representation of our list of students – we'll use gson, Google's JSON library, to do the conversion (in the class Database, we have a Gson attribute gson), so we need to add another dependency in app/build.gradle:
...
dependencies {
// ... as before ...
implementation group: 'com.google.code.gson', name: 'gson', version: '2.10.1'
implementation group: 'org.xerial', name: 'sqlite-jdbc', version: '3.45.0.0'
implementation "com.sparkjava:spark-core:2.9.4"
// ... as before ...
}
...
and also add some lines to our Database file (the import statements for spark and gson, and the creation of the Gson attribute gson):
package demo;
import java.sql.*;
import java.util.*;
import spark.Request;
import spark.Response;
import com.google.gson.*;
/**
* Database is an interface to the college application database, it
* uses JDBC to connect to a SQLite3 file.
*/
public class Database {
/**
* The database connection.
*/
private Connection conn;
private Gson gson = new Gson();
... as before ...
}
We first generate a Student 'POJO', this time with support for both ResultSet and Gson (observe that we translate snake-case to CamelCase, since that's the JSON 'standard'):
$ db-pojo -j -g Student s_id -> id : int s_name -> name : String gpa : double
and get:
class Student {
public final int id;
public final String name;
public final double gpa;
private Student (int id, String name, double gpa) {
this.id = id;
this.name = name;
this.gpa = gpa;
}
public static Student fromRS(ResultSet rs) throws SQLException {
return new Student(rs.getInt("s_id"),
rs.getString("s_name"),
rs.getDouble("gpa"));
}
public static Student fromJson(Gson gson, String json) {
return gson.fromJson(json, Student.class);
}
public String toJson(Gson gson) {
return gson.toJson(this);
}
}
We then write the following method:
public String getStudents(Request req, Response res) {
var found = new ArrayList<Student>();
var query =
"""
SELECT s_id, s_name, gpa, size_hs
FROM students
""";
try (var ps = conn.prepareStatement(query)) {
var resultSet = ps.executeQuery();
while (resultSet.next()) {
found.add(Student.fromRS(resultSet));
}
} catch (SQLException e) {
e.printStackTrace();
}
res.status(200);
return gson.toJson(found);
}
To run this, we run (just as showed above):
$ ./gradlew run
This compiles our program, runs it, and waits for it to finish.
So to test our server, we can open another command line window, and run curl – our server runs on our own computer, which is called localhost (a.k.a. 127.0.0.1), and it runs on port 4567, so we can call our method above to get all students using the curl command:
$ curl -X GET http://localhost:4567/students
[{"id":0,"gpa":4.0,"sizeHs":0},{"id":123,"name":"Amy","gpa":3.9,"sizeHs":1000},{"id":234,"name":"Bob","gpa":3.6,"sizeHs":1500},{"id":345,"name":"Craig","gpa":3.5,"sizeHs":500},{"id":448,"name":"Adam","gpa":4.0,"sizeHs":400},{"id":456,"name":"Doris","gpa":3.9,"sizeHs":1000},{"id":543,"name":"Craig","gpa":3.4,"sizeHs":2000},{"id":567,"name":"Edward","gpa":2.9,"sizeHs":2000},{"id":654,"name":"Amy","gpa":3.9,"sizeHs":1000},{"id":678,"name":"Fay","gpa":3.8,"sizeHs":200},{"id":765,"name":"Jay","gpa":2.9,"sizeHs":1500},{"id":789,"name":"Gary","gpa":3.4,"sizeHs":800},{"id":876,"name":"Irene","gpa":3.9,"sizeHs":400},{"id":987,"name":"Helen","gpa":3.7,"sizeHs":800}]%
$
This is a minified version of the output, if we install a prettyprinter, such as jq, we can make the output more readable:
$ curl -X GET http://localhost:4567/students | jq
[
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 234,
"name": "Bob",
"gpa": 3.6,
"sizeHs": 1500
},
{
"id": 345,
"name": "Craig",
"gpa": 3.5,
"sizeHs": 500
},
...
{
"id": 987,
"name": "Helen",
"gpa": 3.7,
"sizeHs": 800
}
]
(Here I've removed some output). The JSON keys have the same name as the attributes in our POJO (Gson generated them).
Normally one wants the JSON replies from a REST server to be encapsulated in some 'wrapper' object, with the return value in its "data" field, and it can easily be done with a wrapper class:
class DataWrapper {
private Object data;
public DataWrapper (Object data) {
this.data = data;
}
}
We might as well add a method which takes an object, encapsulates it in a DataWrapper, and then returns the JSON version of it (we put it in our Database class):
private String asJsonData(Object object) {
return gson.toJson(new DataWrapper(object));
}
Now we can write
public String getStudents(Request req, Response res) {
... as above ...
res.status(200);
return asJsonData(found);
}
to get (the same list as above, but now inside an object with a "data" field):
$ curl -X GET http://localhost:4567/students | jq
{
"data": [
{
"id": 0,
"gpa": 4,
"sizeHs": 0
},
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 234,
"name": "Bob",
"gpa": 3.6,
"sizeHs": 1500
},
...
{
"id": 987,
"name": "Helen",
"gpa": 3.7,
"sizeHs": 800
}
]
}
Getting a specific student
As we saw in the slides, the endpoint /students gives all students, whereas /students/<id> gives us only the student with a given id (this is a typical pattern in REST services). To add this more specific endpoint we add the following line in App:
void run() {
// ...
get("/students/:sId",
(req, res) -> db.getStudent(req, res, Integer.parseInt(req.params(":sId"))));
// ...
}
Here Spark will pick out the id (:sId), and we can ask the Request for the value with the params-call above – since it is an integer, we can parse it before we call our method in db (we could also pick out the parameter in the getStudent method, but that would require that the method knew what name we gave the parameter in the call in run).
The method getStudent which we call in the line above is pretty much the same as the method we saw above, only this time we insert the student id into the query:
public String getStudent(Request req,
Response res,
int studentId) {
var found = new ArrayList<Student>();
var query =
"""
SELECT s_id, s_name, gpa, size_hs
FROM students
WHERE s_id = ?
""";
try (var ps = conn.prepareStatement(query)) {
ps.setInt(1, studentId);
var rs = ps.executeQuery();
while (rs.next()) {
found.add(Student.fromRS(rs));
}
} catch (SQLException e) {
e.printStackTrace();
}
res.status(200);
return asJsonData(found);
}
If the student is found, it will be the only element in the list, and if there is no student with the given id, we return the empty list.
Using a query string
Sometimes we want to have a way to filter out specific values, if we want just all student with the name "Amy", we want to be able to use the call:
$ curl -X GET http://localhost:4567/students?name=Amy | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
}
]
}
The exact format of the query string depends on where we write it, when I write the call above in my terminal window, it adds a backslash before the question mark, and before the equal sign, so it looks like:
$ curl -X GET http://localhost:4567/students\?name\=Amy
but it depends on what operating system you're on, and what tools you use.
As an example we can also add a way to find only student with a minimum gpa (now I've copied the call verbatim from my terminal window):
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9 | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 456,
"name": "Doris",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 876,
"name": "Irene",
"gpa": 3.9,
"sizeHs": 400
}
]
}
We can also combine the two queries:
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9\&name\=Amy | jq
{
"data": [
{
"id": 123,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
},
{
"id": 654,
"name": "Amy",
"gpa": 3.9,
"sizeHs": 1000
}
]
}
The query parameters are sent as a part of the URL, and many of the symbols we might want to use in our queries, such as spaces, commas and periods, aren't allowed in a URL. Fortunately we can use URL encoding (also known as Percent-encoding), which is a standardized way of translating a string with 'illegal' characters into a safe string, and back again. As an example, using URL encoding we can translate the string
to be, or not to be
into
to%20be%2C%20or%20not%20to%20be
In Java we can import
import java.net.URLDecoder;
which gives us the method URLDecoder.decode(s, "utf-8") to decode a URL encoding string into UTF-8 (which is the charset we want to work with).
To add query parameters to our requests, we write an updated version of the getStudents method we saw above – now we have to check which query parameters are in req (for requests without parameters, it's going to work as before). One way to do this is to first create a query which is amenable to the addition of zero or more extra conditions.
So instead of
SELECT s_id, s_name, gpa, size_hs FROM students
I add the seemingly nonsensical WHERE TRUE:
SELECT s_id, s_name, gpa, size_hs FROM students WHERE TRUE
This is a very pragmatic trick, and the point of it is that we now can add zero or more lines with additional conditions:
SELECT s_id, s_name, gpa, size_hs
FROM students
WHERE TRUE
AND s_name = ?
AND gpa > ?
We can ask the Request (req) for potential query parameters using the queryParams-method – to avoid lots of code duplication I've introduced a small helper function (checkParam) below – in it I URL-decode every parameter, so we allow the users' queries to contain any sequence of characters.
And once I've added placeholders for the parameters in the query, I look through the generated list of parameter values, and insert them into my query using setString:
private String checkParam(Request req,
String paramName,
String condition,
List<String> params) {
var param = req.queryParams(paramName);
if (param != null) {
params.add(URLDecoder.decode(param, "utf-8"));
return '\n' + condition; // put each condition on its own line
}
return ""; // nothing to add, since the parameter was absent
}
public String getStudents(Request req, Response res) {
var found = new ArrayList<Student>();
var query =
"""
SELECT s_id, s_name, gpa, size_hs
FROM students
WHERE TRUE
""";
var params = new ArrayList<String>();
query += checkParam(req, "name", "AND s_name = ?", params);
query += checkParam(req, "minGpa", "AND gpa >= ?", params);
try (var ps = conn.prepareStatement(query)) {
var idx = 0;
for (var param : params) {
ps.setString(++idx, param);
}
var rs = ps.executeQuery();
while (rs.next()) {
found.add(Student.fromRS(rs));
}
} catch (SQLException e) {
e.printStackTrace();
}
res.status(200);
return asJsonData(found);
}
To use this, the caller must URL-encode her query parameters – for simple strings as above, it will make no difference:
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9\&name\=Amy
but to look for "Anna Karin", the encoding looks a bit different:
$ curl -X GET http://localhost:4567/students\?minGpa\=3.9\&name\=Anna%20Karin
Posting a student
When the user posts a student, she must provide a JSON object describing the student in the body of the request.
We tell Spark which method to call with:
void run() {
// ...
post("/students", (req, res) -> db.postStudent(req, res));
}
}
and in the method, we use the Gson library in the reverse direction – we ask it to generate a POJO (Student) from the JSON string in the request body. We can do it in two steps, either using the fromJson method in our POJO:
var body = req.body(); var student = Student.fromJson(gson, body);
or calling gson directly:
var body = req.body(); var student = gson.fromJson(body, Student.class);
The latter version works even if we generate our POJO without explicit Gson support.
Once we have our student, its pretty straightforward to create an INSERT statement, we just extract each of the attributes from the POJO, and set the corresponding parameter in our statement.
One problem is how to generate the student s_id – normally we'd like the database to come up with this key (it's an invented key), but doing so using JDBC is so cumbersome that we'll just skip it in this course, and instead generate the key outside the database (in Python it's easy to insert new values and get back keys generated by the database, see below).
A common convention in REST apis is to return the url of a newly added resource – in this case we actually know what that url will be before we make the POST call (since we provide the resource id ourselves), so it's easy (see the last line):
public String postStudent(Request req, Response res) {
var body = req.body();
var student = Student.fromJson(gson, body);
var statement =
"""
INSERT
INTO students(s_id, s_name, gpa, size_hs)
VALUES (?,?,?,?)
""";
try (var ps = conn.prepareStatement(statement)) {
ps.setInt(1, student.id);
ps.setString(2, student.name);
ps.setDouble(3, student.gpa);
ps.setInt(4, student.sizeHS);
ps.executeUpdate();
res.status(201);
} catch (SQLException e) {
e.printStackTrace();
res.status(400);
}
res.status(201);
return String.format("http://localhost/students/%d", student.id);
}
This is a bit of a simplification, since one normally returns the URL of the new resource as a part of the response header, but returning it this way will do fine for this course.
In the Python version below, I show how we can return a generated value in a simple way (this is also described in the problem text for lab 2).
To use curl to post a student using this endpoint, we need to:
- tell the server that we're sending JSON data, hence the
-Hflag with the content typeapplication/json, and - provide the JSON object using the
-dflag and a string (observe that we can choose between'and"for string delimiters in both JSON and the shell, so if we use"in our JSON object, we need to use'for our-dargument).
As usual, the $ sign below is just the prompt, it's not part of the command:
$ curl -X POST http://localhost:4567/students -H 'Content-Type: application/json' -d '{"id": 297, "name": "Anna Karin", "gpa": 3.8, "sizeHS": 400}'
The reply should be http://localhost/students/297, and it is the URL of the new resource.
Observe that we don't have to URL encode Anna Karin's name when we send it in the request body (it's not part of the URL), but we'll need to URL encode it if we want to search for it:
$ curl -X GET http://localhost:4567/students\?name\=Anna+Karin
{"data":[{"id":297,"name":"Anna Karin","gpa":3.8,"sizeHS":400}]}%
Getting applications from a specific student
We saw above that /students/123 is a specific student (one of the Amys), and to get her applications we can write /students/123/applications – to implement this we first add the 'route':
void run() {
// ...
get("/students/:sId/applications",
(req, res) -> db.getStudentApplications(req, res, Integer.parseInt(req.params(":sId"))));
// ...
}
and then write the following method:
public String getStudentApplications(Request req,
Response res,
int studentId) {
var found = new ArrayList<Application>();
var query =
"""
SELECT s_id, c_name, major, decision
FROM applications
JOIN students
USING (s_id)
WHERE s_id = ?
""";
try (var ps = conn.prepareStatement(query)) {
ps.setInt(1, studentId);
var rs = ps.executeQuery();
while (rs.next()) {
found.add(Application.fromRS(rs));
}
} catch (SQLException e) {
e.printStackTrace();
}
res.status(200);
return asJsonData(found);
}
It requires a POJO (Application) to use, and it can be defined as:
class Application {
public final int id;
public final String college;
public final String major;
public final boolean decision;
private Application (int id, String college, String major, boolean decision) {
this.id = id;
this.college = college;
this.major = major;
this.decision = decision;
}
public static Application fromRS(ResultSet rs) throws SQLException {
return new Application(rs.getInt("s_id"),
rs.getString("c_name"),
rs.getString("major"),
rs.getString("decision").equals("Y"));
}
}
How to extract values from a query in Python
Python has several features which simplifies working with query results and JSON objects a lot, some of them are:
- lists,
- list comprehensions,
- tuples,
- dictionaries, and
- the
jsonlibrary.
We can easily define a list with simple values, such as the smallest primes:
small_primes = [2, 3, 5, 7, 11, 13]
If we wanted a list of the squares of these primes, we could write:
squares_of_small_primes = []
for p in small_primes:
squares_of_small_primes.append(p*p)
but this is verbose, and relies on mutable state. Python allows us to instead write this as:
squares_of_small_primes = [p*p for p in small_primes]
It means that we run the loop inside the list, and generates values which will be returned in one fell swoop – it's called a list comprehension (Python also have some very useful cousins to list comprehensions, such as set comprehensions, dictionary comprehensions, and generator comprehensions).
Another very useful feature is tuples, which allows us to pack related values in very flexible containers – let's say we wanted to have a list of some countries and their capitals, we could define it as:
geography = [("Sverige", "Stockholm"),
("Danmark", "Köpenhamn"),
("Norge", "Oslo")]
We can iterate through this list using a simple loop:
for (country, capital) in geography:
print(f"{country} har huvudstaden {capital}")
We don't even need the parenthesis around the tuple in the loop header:
for country, capital in geography:
print(f"{country} har huvudstaden {capital}")
We also have dictionaries, which are a very pragmatic version of the Maps we find in Java. We can define a dictionary with the names of the smallest integers
numbers = {0: "zero", 1: "one", 2: "two", 3: "three"}
for k in range(0,5):
print(f"{k} is {numbers.get(k, 'unknown')}")
which gives the output
0 is zero 1 is one 2 is two 3 is three 4 is unknown
By combining lists, tuples, list comprehensions and dictionaries, we can generate a list with dictionaries:
geography = [("Sverige", "Stockholm"),
("Danmark", "Köpenhamn"),
("Norge", "Oslo")]
nordic_capitals = [{"country": country,
"capital": capital} for country, capital in geography]
print(nordic_capitals)
which gives
[{'country': 'Sverige', 'capital': 'Stockholm'}, {'country': 'Danmark', 'capital': 'Köpenhamn'}, {'country': 'Norge', 'capital': 'Oslo'}]
and this is very close to the kind of JSON object we want to return from our REST calls.
If we import the json library, and use the json.dumps function, we can turn this into a JSON object directly:
import json
geography = [("Sverige", "Stockholm"),
("Danmark", "Köpenhamn"),
("Norge", "Oslo")]
nordic_capitals = [{"country": country,
"capital": capital} for country, capital in geography]
print(json.dumps(nordic_capitals))
We'll get:
[{"country": "Sverige", "capital": "Stockholm"}, {"country": "Danmark", "capital": "Köpenhamn"}, {"country": "Norge", "capital": "Oslo"}]
We can use this technique to convert the result of a sqlite3 query into a JSON object.
Common SELECT statements will give us lists like the geography list above
– let's say we use the query:
c = db.cursor()
c.execute(
"""
SELECT s_id, s_name, gpa
FROM students
"""
)
Our cursor would now contain a sequence of tuples, each containing three values (akin to the list of two-tuples we had above) – to generate a list of dictionaries with these values we could write:
found = [{"id": s_id,
"name": s_name,
"gpa": gpa} for s_id, s_name, gpa in c]
and we could use this to generate a JSON object using json.dumps, or let Bottle handle it (Bottle will, surprisingly, not convert list automatically, but we'll anyways wrap the result into another object first – more on that in the text above).