Mål
Efter laborationen ska du
- kunna använda Python-biblioteket NumPy för enkla beräkningar, med såväl reella som komplexa tal,
- känna till några standardfunktioner och kunna definiera egna funktioner, samt
- kunna arbeta med vektorer och matriser i NumPy.
Laborationen avslutas med en temauppgift, där du får träna på att konstruera script i Python.
-
 Logga in på datorn och starta Visual Studio Code (VS Code). På LTH:s Linux-datorer klickar du på Ubuntu-ikonen, som finns överst till vänster på skärmen (och ser ut som bilden här till höger). Skriv
Logga in på datorn och starta Visual Studio Code (VS Code). På LTH:s Linux-datorer klickar du på Ubuntu-ikonen, som finns överst till vänster på skärmen (och ser ut som bilden här till höger). Skriv vs codeoch tryck Return.På samma Linux-datorer kan du enkelt få dina två fönster (VS code + denna webbläsare) sida vid sida. Klicka och dra i VS code-fönstrets titelrad, och dra fönstret till skärmens kant (vänster eller höger). När du ser en "skugga" över halva skärmen släpper du fönstret där. Gör därefter likadant för webbläsaren, fast dra den istället till den andra kanten.
Starta en terminal i VS Code genom att välja Terminal → New Terminal. Då öppnas en terminal i nedre delen av fönstret. Starta en Python repl i terminalen genom att skriva kommandot
pythoni terminalfönstret.Gör några enkla beräkningar (de vanliga räknesätten) i terminalen och prova att använda variabler.
-
Med NumPy kan vi hantera såväl reella som komplexa tal. I terminalen, börja med att importera NumPy med alias np så här:
import numpy as np. Nu kan du komma åt variabler och funktioner inumpygenom att skriva np.namnet, till exempelnp.pi.Skriv ut följande värden:
- π
- √3
- √–3
- √i
- eπi
-
Komplexa tal presenteras alltså i rektangulär form (det vill säga med real- och imaginärdel). Ibland är vi istället intresserad av talets polära form (absolutbelopp och argument).
Tilldela variabeln z något av de komplexa värdena i uppgift 2(c)-(e) ovan. Skriv ut absolutbelopp och argument för z.
Varför funkar intenp.arg(z)?Funktionen
np.angle(z)ger argumentet (vinkeln) för ett komplext talz.Tilldela z ett annat av de tre komplexa värdena och skriv ut real- och imaginärdel för z.
Stäng python-repl på något av följande sätt:
- Skriv
exit()följt av Enter. - Windows: Ctrl + Z och sen Enter.
- MacOS och Linux: Ctrl + D.
- Stäng terminalens panel genom att klicka på krysset uppe till höger i panelen.
- Skriv
-
Ofta är det praktiskt att spara en sekvens av kommandon i en fil. Sådana script är alltså ett slags små program.
Klicka File →New Text File, då skapas en fil med namnet Untitled. Spara filen genom att välja File →Save, välj en folder att spara i och namnge filen
lab1.py. Du kan också använda tangentbordskommandona (Windows, Linux) ctrl-N eller (Mac) cmd--N för att skapa en ny fil och (Windows, Linux) ctrl-S eller (Mac) cmd--S för att spara en fil.Lägg till en kodrad som skriver ut något med
print()och exekvera filen genom att trycka på pilen Run Code uppe till höger. Texten skrivs ut i terminalen. Låt scriptet förbli öppet – du kommer att bygga vidare på det.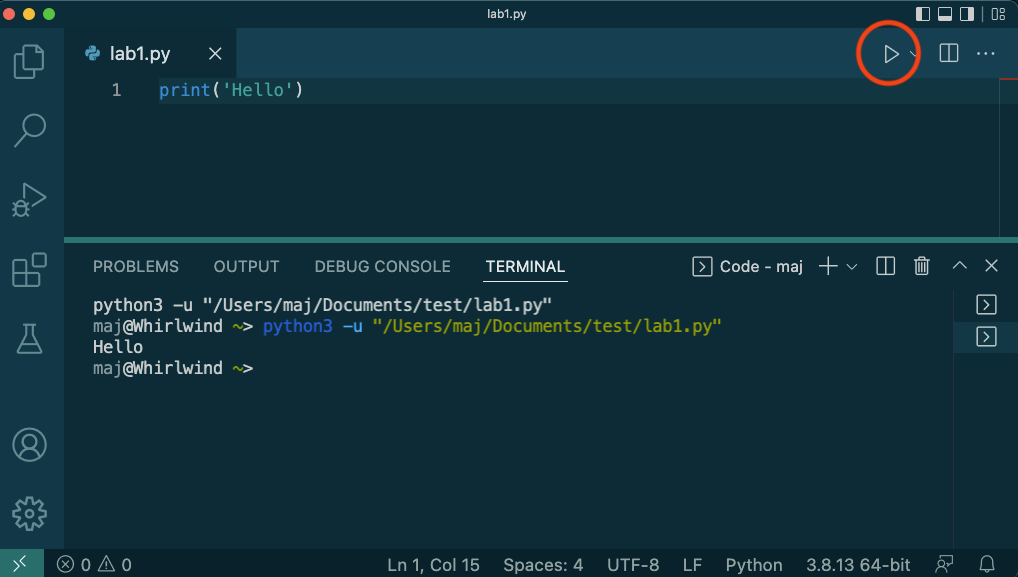
Lägg till följande rader i ditt skript.
# Komplexa tal a = 3 + 2j; b = 5 - 1j; x = a * bDen första raden är en kommentar.
Klicka på pilen Run Code. Alla tre satserna i ditt script körs, men du kan inte se resultatet från dem. Varför? Ändra i koden så att x skrivs ut.
Du kan även köra samma script genom att ange dess namn i terminalen. Välj File →Open Folder och välj foldern för labben. Om du klickar på filikonen ser du alla filer som finns i foldern, klicka på en fil för att öppna den
 .
. Öppna terminalen, nu har terminalens prompt också folderns path.
Skriv
python lab1.pyi terminalen och kontrollera att du får samma svar som i förra uppgiften. -
Inför de följande uppgifterna ska du skapa ett nytt avsnitt i ditt script.
Lägg till en rad med en hashtag och kommentar sist i ditt script och importera numpy, exempelvis så här:
# Funktioner import numpy as npLåt oss definiera funktionen gx som följer:
gxe–0.1x cos xDefiniera gx i ditt script. Gör definitionen på en enda rad med en lambda-function.
Kontrollera med
print()att funktionen ger rätt resultat, använd gärna en sträng med som förklarar vad talet är (till exempel'g(0) är'):print('###### Uppgift 5 ######') print('g(0) är', g(0)) g(0) är 1.0 print('g(2) är', g(2)) g(2) är -0.3407122128772617Om något inte stämmer, justera ditt script och exekvera koden igen.
-
Vi är nu intresserade av funktionens värden i intervallet 0 ≤ x ≤ 10.
Lägg till en rad i ditt script, där en vektor av 100 sådana x-värden skapas, jämnt fördelade.
Kontrollera att värdena verkar rimliga:
print('###### Uppgift 6 ######') print('x[0] är', x[0]) x[0] är 0.0 print('x[26] är', x[26]) x[26] är 2.6262626262626263 print('x[99] är', x[99]) x[99] är 10.0Använd funktionen
type()för att ta reda på datatypen förx. Hur många element harx?Nu vill vi beräkna värdet av funktionen
gför alla dessax-värden.Lägg till en rad i ditt script, så att en motsvarande vektor
yav funktionsvärden skapas.NumPy-funktioner, till exempel
np.cos()ochnp.exp()kan ta vektorer som argument och returnerar då en vektor där funktionen beräknats elementvis. Kan samma teknik användas föry?y = g(x)Kontrollera att även dessa värden verkar stämma:
print('y[26] är', y[26]) y[26] är -0.6691555248591664 print('g(x[26]) är', g(x[26])) g(x[26]) är -0.6691555248591664I det senare kommandot är
x[26]värdet av element 27 i vektornxeftersom vektorerna är nollindexerade, och det värdet används i sin tur som parameter till funktioneng. Resultatet ska överensstämma med element på index 26 i vektorny.För att plotta funktionen använder vi Python-biblioteket
matplotlib, börja med att importera det med kodradenimport matplotlib.pyplot as plt.Låt ditt script plotta funktionen (gx enligt ovan) för värdena 0 ≤ x ≤ 10.
Ditt
Funktioner-avsnitt ska nu se ut i stil med följande (fast du ersatt...med något annat):# Funktioner # med utskrifter på olika ställen mellan raderna nedan import ... g = ... x = ... y = ... import ... plt.figure() # Skapar ett nytt fönster. plt.plot(...) # Lägg till kod för att rita ut funktionen plt.title('Uppg 6') plt.show()I fortsättningen ska du för varje uppgift (som i exemplet ovan) tydligt skriva ut vilken uppgift utskrifter hör till, vad varje värde motsvarar och sätta titlar i dina plottar så att det går att följa programmets exekvering när du ska redovisa. Fråga din labbhandledare om du är osäker.
-
Ibland vill vi (approximativt) beräkna derivatan för en given funktion. Då kan vi utgå från derivatans definition:
f'x≈fx + h – fxh(om h är litet)I analysen låter vi h gå mot noll. Här måste vi bestämma oss för ett värde, och låter därför istället h vara ett "lagom" litet tal. Vi kan exempelvis sätta h till 10–6:
h = 1e-6Definiera en funktion
derivsom tar två parametrar: en funktion f, och ett x-värde. Funktionenderiv(f,x)ska beräkna (approximera) f'x enligt ovan.Du definierar funktionen med något i stil med
deriv = lambda f,x: ...där den saknade delen (
...) hämtas från derivatans definition ovan. Parameternfär en funktion, ochxär ett x-värde vi vill beräkna derivatan för.Derivatans definition kan skrivas i Python som
deriv = lambda f, x: (f(x + h) - f(x)) /hAnvänd en funktion med känd derivata för att testa din
deriv-funktion för något x-värde. Hur nära kommer approximationen?Vi vet ju exempelvis att derivatan av sin x är cos x. När du anger
sinsom parameter i Pyhton måste du skrivanp.sin(utan parenteser).Vad ger följande kommandon för resultat? Är resultaten rimliga?
print(deriv(np.sin,0.3)) print(np.cos(0.3)) print(deriv(np.sin,0.3) - np.cos(0.3)) -
Ett annat sätt att övertyga sig om att
derivger rimliga resultat är att plotta en funktion tillsammans med sin (approximerade) derivata. Här kan vi göra detta för funktionen g(x) i uppgift 6.gxe–0.1x cos xPlotta gx och g'x i samma diagram, för 0 ≤ x ≤ 10. Använd
derivför att approximera g'x, och gör grafen för g'x röd.Tips om hur du väljer anger färg som argument finns i dokumentationen för plot och colors.
Hur får man två grafer i samma bild?För att få flera grafer i samma bild kan du skriva flera
plt.plot(...)efter varandra, närplt.show()anropas ritas alla plottar i samma bild.Verkar den approximerade derivatan rimlig?
Derivatan ska exempelvis vara noll vid funktionens lokala maxima/minima. Derivatan ska i sin tur ha ett lokalt maximum då funktionen växer som brantast.
För att se axlarna tydligare kan du använda
plt.grid().Vi ska nu se hur man kan utrusta grafen med rubriker och spara bilden som en fil.
Lägg till följande rader i ditt script, och notera hur fönstret med graferna förändras:
plt.title('Uppg 8: Funktionen och dess derivata') plt.legend(['funktion', 'derivata']) plt.savefig('funktionsbild.png')Det sista kommandot ovan skapade en fil som heter
funktionsbild.pngsom hamnar i samma folder som dina Pythonfiler. Sådanapng-bilder kan importeras i ett ordbehandlingsprogram (LaTeX, Word eller något annat) och användas i exempelvis en labbrapport. -
Bent, Alva och Kit försöker derivera funktionen gx ovan analytiskt. Det är länge sedan de läste analys, och endast ett vagt minne av deriveringsreglerna återstår. De kommer fram till olika svar.
h1xe–0.1x cos x – 0.1e–0.1x sin x(Bent)h2x–0.1e–0.1x cos x – e–0.1x sin x(Alva)h3x–0.1e–0.1x cos x – 0.1e–0.1x sin x(Kit)Vi ska nu använda NumPy för att försöka jämföra dessa tre kurvor h1x, h2x och h3x med din beräknade derivata
deriv(g,x). Du ska alltså inte använda dina kunskaper om deriveringsreglerna för den här uppgiften.Skapa fyra vektorer av derivatavärden: en från
deriv(g,x), en från h1x, en från h2x och en från h3x.y0 = deriv(g,x) y1 = h1(x) y2 = ... # på motsvarande sätt y3 = ... # på motsvarande sättSkapa tre nya vektorer, en för var och en av de tre funktionerna. Varje vektor ska innehålla differenserna mellan funktionens värden och den beräknade derivatans.
Varje vektor anger alltså hur mycket respektive funktion avviker från den "riktiga" (beräknade) derivatan.
Med beteckningarna från föregående ledtråd blir
d1 = y1 - y0 d2 = ... # på motsvarande sätt d3 = ... # på motsvarande sättVi har nu tre differensvektorer, en för varje funktion. De är rätt jobbigt att läsa igenom och jämföra tre vektorer om hundra element. Istället vill vi ha ett enda mått på respektive differensvektors storlek.
Här är funktionen
norm, som beräknar en vektors magnitud (euklidisk norm), användbar. Den är ett enkelt och bra storleksmått på en vektor. Läs gärna om den euklidiska normen på Wikipedia. Funktionen finns i NumPy-modulen för linjär algegra och anropas med sitt fullständiga (och ganska långa) namn:np.linalg.norm(x)Tips: För att slippa skriva långa namn, kan vi istället importera funktionen:
from numpy.linalg import norm norm(x)Vilken av de tre funktionerna h1x, h2x och h3x kan anses ligga närmst den beräknade derivatan?
Med beteckningarna från föregående ledtråd kan vi räkna ut
norm(d1) norm(d2) norm(d3)Ett litet resultat fromnormbetyder att vektorn innehåller små värden. En av normerna ligger nära noll, och motsvarar alltså den korrekta derivatan. -
Vi söker en matris med följande utseende:
MBilda matrisen M ovan med hjälp av NumPy-funktionerna
eye,onesochvstack,hstackellerconcatenate.Ovan till höger finns en knapp []. Om du trycker på den så genereras en ny uppgift. Pröva!
-
Betrakta följande ekvationssystem (med tre obekanta , och ):
Lös ekvationssystemet genom att skriva om det på matrisform och använda
np.linalg.solve().Ekvationssystemet kan skrivas A·xb, där
AxbMed dessa beteckningar söker vi kolonnvektorn x.
Kontrollera att din lösning uppfyller ekvationerna. Även det kan göras enkelt i NumPy — hur då?
På matrisform skriver vi ju A·xb, där x är lösningen du fann ovan. Med dessa beteckningar ska både vänsterledet
A · xoch högerledetbska ha samma värde.Kontrollera detta genom att skriva ut dessa båda värden i NumPy med hjälp av
np.dotVarför ger multiplikationstecknet
*fel svar?A * x"Vanliga" matematiska funktioner anropas elementvis på en
np.array, vilket vi sett i uppgift 10. Detta gäller också för funktioner som får flera vektorer som argument, till exempel blir[a, b, c] * [x, y, z] = [ax, by, cz]MatrisenArepresenteras som en vektor där varje element också är en vektor, så vid uträkningenA * xblir första raden iAmultiplicerad med första elementet ix, andra raden iAmed andra elementet ixosv, vilket ger en ny matris och inte en kolonnvektor.x= -
Betrakta matrisen A nedan:
A1 1 –1 2 1 1 4 3 –1 Bestäm determinanten för A. Använd en av NumPys inbyggda funktioner.
Determinant? Vad är det?Determinanter behandlas i kursen i linjär algebra, som du kanske ännu inte läst. Det är inget bekymmer här.
Determinanten är ett värde som man kan beräkna för en given matris, och som säger oss något om matrisens egenskaper. Exempelvis är det intressant, visar det sig, att veta huruvida matrisens determinant är noll eller ej.
Vilken inbyggd funktion ska jag använda?En bra gissning är att funktionens namn påminner om "determinant". Pröva att söka efter "matrix determinant" på NumPys dokumentation.
Om matrisen heter exempelvis
Akan vi skrivanp.linalg.det(A)Använd NumPy för att lösa följande ekvationssystem:
x1 + x2 – x322x1 + x2 + x334x1 + 3x2 – x34Du får sannolikt fram ett märkligt felmeddelande. Hur ska vi tolka detta? Jämför med matrisen A ovan.
I kursboken i linjär algebra kan står följande:
Huvudsatsen. För kvadratiska matriser A är följande villkor ekvivalenta:
- [...]
- (c)
- ekvationssystemet AX=Y är lösbart för alla Y,
- (d)
- A är inverterbar,
- [...]
- (f)
- det A ≠ 0 .
Ur: Gunnar Sparr, Linjär algebra, andra upplagan, Studentlitteratur 1995, s. 212.
Ekvationssystemet saknar lösning (vilket också indikeras av att determinanten är noll).
-
Du har redan sett att Python och NumPy kan användas för att beräkna kvadratrötter, till och med komplexa sådana. Här ska vi titta närmare på hur en sådan beräkning kan fungera.
Kvadratroten av ett positivt, reellt tal S kan beräknas iterativt så här (mer om algoritmen nedan):
xk+1xk + ( S / xk )2Här beräknas alltså successivt allt bättre approximationer xk+1 till √S, hela tiden utifrån den föregående approximationen xk. Med "tillräckligt" många upprepningar får vi en approximation av √S. Som startvärde kan vi exempelvis gissa
x0S / 2Låt oss beräkna √50 med sex decimaler. Då blir
x0 S / 225x1x0 + ( S / x0 )213.525 + (50 / 25)2x2x1 + ( S / x1 )28.60185113.5 + (50 / 13.5)2x37.207277
x47.072355
x57.071068
x67.071068
I det här fallet får vi alltså sex korrekta decimaler efter fem iterationer. Den sjätte iterationen bekräftar att vi är klara.Skriv ett script som läser in ett tal S från terminalen, och därefter skriver ut de tio första approximationerna av √S med algoritmen ovan.
Använd
input()för att läsa in en textsträng från terminalen. Typomvandla strängen till ett flyttal med funktionenfloat(), som anropas så här:x = float(strängen med talet).Notera: Ditt script ska inte använda sig av den inbyggda
sqrt-funktionen.Kontrollera att ditt script fungerar, exempelvis genom att jämföra med exemplet ovan.
-
Som du kanske ser konvergerar beräkningen ganska fort. Det är sällan nödvändigt med tio iterationer, men det är svårt att på förhand avgöra exakt hur många som behövs.
Ändra ditt script så att det inte gör ett fixt antal iterationer (tio ovan), utan beräknar nya värden tills serien konvergerar. Låt scriptet skriva ut antalet iterationer som behövdes.
Använd följande kriterium för konvergens:
xk – xk–1 < 10–6Tips: Om ditt program fastnar i en oändlig loop kan du bryta det genom att klicka i kommandofönstret och trycka Ctrl-C.
Du behöver två x-värden för iterationen: en variabel för nuvarande x-värde, och en för det föregående. Välj deras startvärden på ett sådant sätt att
while-satsen inte avbryts från början.Du använde NumPys funktion för absolutbelopp i en av laborationens första uppgifter.
Om ditt script inte verkar konvergera, utan fastnar i en oändlig loop, fundera då på ditt
while-villkor.Lägg in en ny rad i din loop, där båda variablerna skrivs ut med 6 decimalers noggrannhet (om variablerna exempelvis heter
x1ochx2):print('{:.6f} {:.6f}'.format(x1, x2))Här ska de första raderna vara olika, men efter några iterationer ska de två värdena bli lika. Om värdena är helt lika redan från början så behöver du titta närmare på i vilken ordning dina variabler får sina värden. Hur ska du göra för att komma ihåg både det nuvarande och det förra värdet?
- Använder du
<eller>i dittwhile-villkor? Vilket ska villkoret vara för att loopen ska fortsätta?
-
När du kommit hit är du klar med den första NumPy-laborationen. Läs igenom uppgifterna igen och se till att du förstår dina lösningar inför redovisningen.
Grunder: komplexa tal och enkla script
För att räkna kvadratroten av negativa tal kan vi använda modulen emath: np.emath.sqrt(-1).
j istället för i för imaginära tal?Python använder en konvention från elektroniken, där betecknar i ström så istället används j för det imaginära talet j2 = -1.
Funktioner
Matriser och ekvationssystem
Tema: från kilskrift till Python-script
Bakgrund: mer om algoritmen

Approximationstekniken ovan användes av babylonierna (i nuvarande Irak) kring 1600–1800 f.Kr., även om de naturligtvis inte använde samma symboler som oss. De använde ett positionsbaserat talsystem baserat på basen 60, och alltsedan dess delar vi upp timmar i 60 minuter, och minuter i 60 sekunder. Och de hade alltså även en metod för att beräkna kvadratrötter.
Det är inte helt klart om babylonierna gjorde mer än en iteration i sina kvadrotsberäkningar, men vi vet att de kände till approximationen ovan. De kände också till √2 med en noggrannhet motsvarande ungefär sex decimaler. I alla händelser beskrev Heron (ca 10–70 e.Kr.), verksam i Alexandria i nuvarande Egypten, den iterativa algoritmen ovan. Idag kan vi även komma fram till samma algoritm om vi utgår från Newton-Raphsons metod. Då ser vi problemet som att söka nollställen till funktionen
Persondatorer har idag ofta en särskild instruktion för kvadratrotsberäkning, men även sådan hårdvara använder en iterativ algoritm av ovanstående typ. I många tekniska tillämpningar använder man dessutom enklare processorer, som saknar sådana instruktioner. Då kan man beräkna kvadratrötter på det sätt som du prövat här, precis som babylonierna gjorde för närmare fyratusen år sedan.