Camera focus controlled by face detection on GPU
MSc Thesis
Lund University
Karl Berggren & Pär Gregersson
Advisor: Jon Hasselgren
Abstract
This master thesis investigates the possibility to use the GPU of a mobile platform to detect faces and adjust the focus of the camera accordingly. Requirements for such an application are given, and different methods for face detection are described and evaluated according to these requirements. A GPU implementation of the cascade classifier is described. A CPU reference implementation with results is also presented. Methods for setting focus correctly when faces are detected are discussed. Issues when working with OpenGL ES 2.0 are described, and finally future work in the area is proposed.
Introduction
The work plan was to study existing face detection algorithms, in order to find one suitable for GPU implementation. We were supposed to get familiar with the supplied platform and set up an image flow from the camera to the screen. The selected face detection algorithm should be used to detect faces and adjust the focus of the camera accordingly. We were given access to an ARM based platform with OpenGL ES 2.0 acceleration and a QVGA touch screen emulating a mobile device. The platform had a single core Universal Scalable Shader Engine for both vertex and fragment program execution. The hardware platform also had a 5 megapixel camera with autofocus and camera drivers implementing Video For Linux 2.
Face detection method
We chose to use Haar feature based detection. This method is based on comparing the sum of intensities in adjacent regions inside a detection window. Typically two or more adjacent regions are combined, forming what is commonly referred to as a Haar-like feature. Features make use of the fact that objects often have some general properties. An example for faces is the darker region around the eyes compared to the forehead. Several features are tested within a detection window to determine whether the window contains a face or not. There are many types of basic shapes for features, as illustrated in this figure .
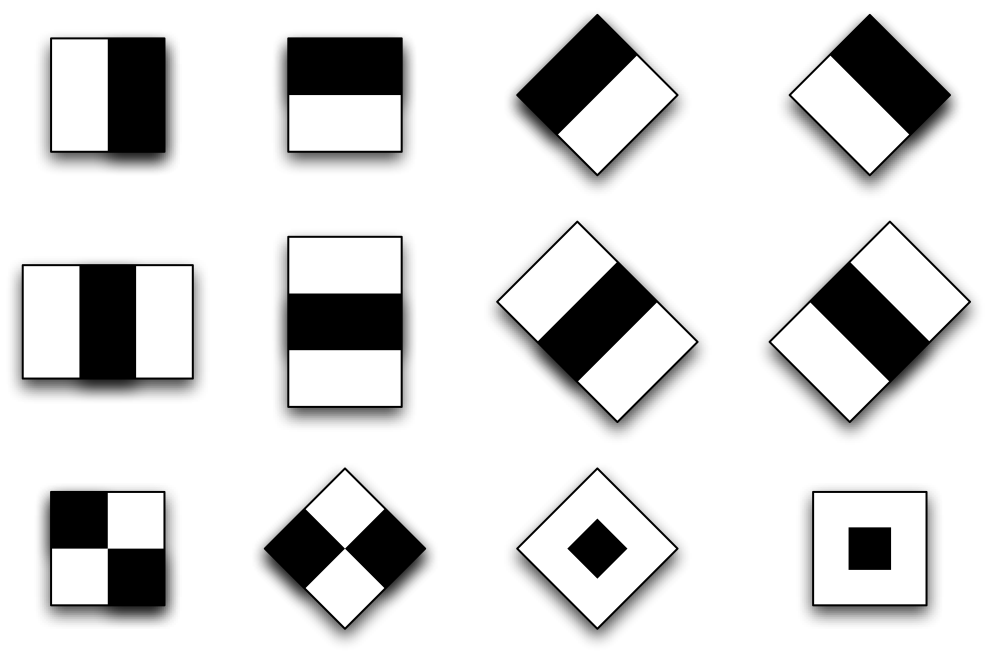
By varying the position and size of these features within the detection window, an overcomplete set of different features is constructed. The creation of the detector then consists of finding the best combination of features to separate faces from non-faces. This is commonly referred to as the training of the detector.
The main advantage of this method is that the detection process consists mainly of additions and threshold comparisons. This makes the detection fast, even on systems with limited resources, like mobile devices. On the other hand, the accuracy of the face detector is highly dependent on the database used for training. The main disadvantage is the need to calculate sums of intensities for each feature evaluation. This will require lots of lookups in the detection window, depending on the area covered by the feature. Fortunately, Viola and Jones [1] provide the integral image as a solution to this problem. Using this technique, they successfully implemented a real-time face detector on an embedded system. The use of the integral image allows a Haar based detector to be implemented on GPU, since it is possible to calculate the sum of a region using only a few lookups.
The cascade
By collecting the features that best separates faces from nonfaces in the database a cascade was created. The detection process then consists of evaluating images using the cascade by trying to discard images not containing faces as early as possible. This will optimize the number of features that has to be evaluated in order to detect faces as only faces will have to be evaluated by all features in the cascade. 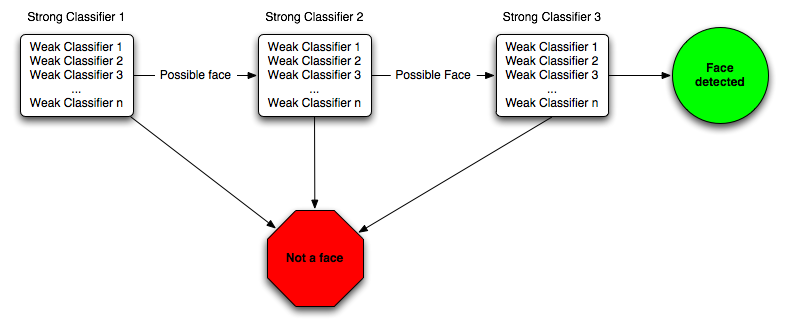
GPU Implementation
The cascade is implemented on GPU using a ping pong technique with two textures and a frame buffer object as described in the image below.
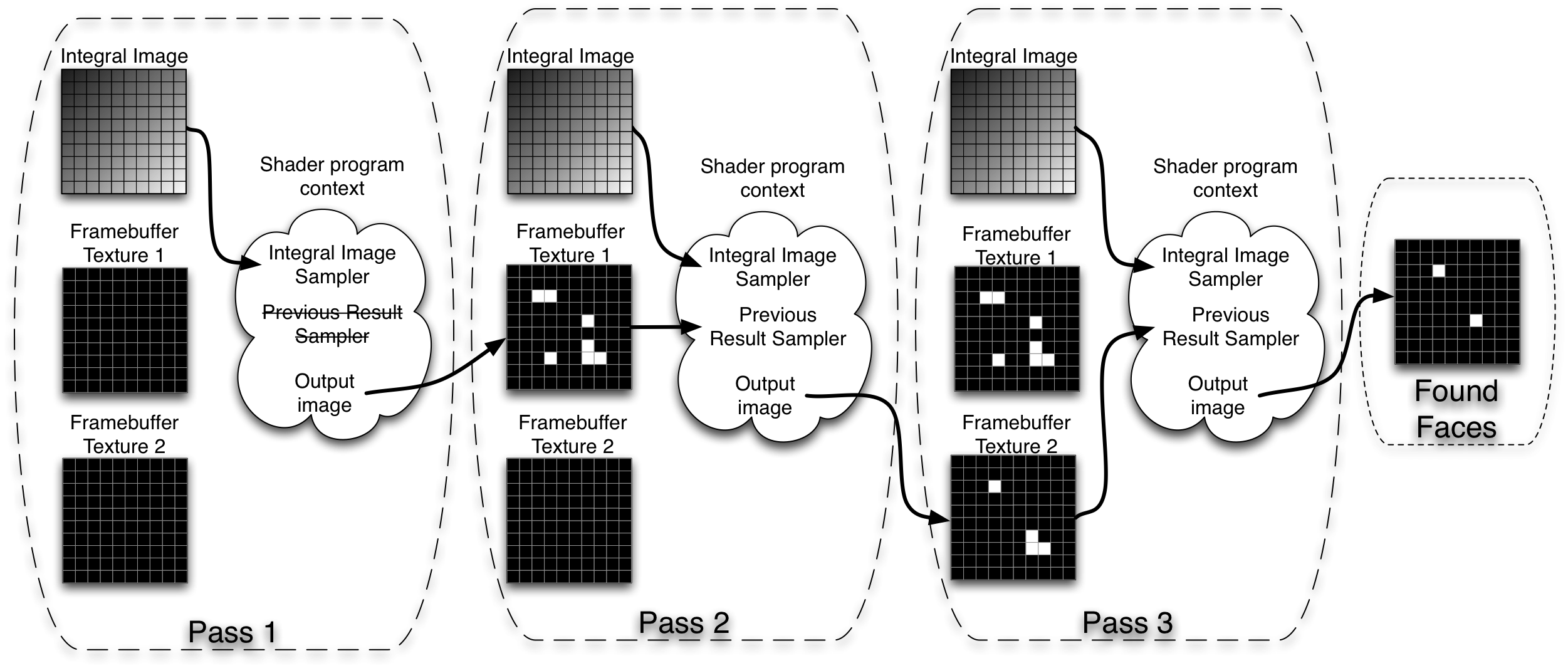
As illustrated, the fragment shader code is used to evaluate parts of the cascade. The reason for dividing this process is the length limitation of shader program and the size of the full cascade.
Faces found in each step are marked with white pixels. Each step will then only evaluate the pixels marked by the previous steps. All other pixels will be discarded. The final result of the detection will be found in the gpu output from the last pass.
Results and issues
Our detector as described above was able to run on the target platform using our framework for controlling the camera and screen. However, the GPU of the embedded device was not able to execute the shader code fast enough for real time performance. Therefore the framework could only be run using a reference CPU implementation of the detection framework. The framerate achieved using this setup was between 1-2 frames per second depending on the number of faces detected. Below is a sample detection using our final cascade.
As for the autofocus, the facedetector is used to select which regions to use for contrast measurement in order to focus on the faces found. Unfortunately, the supplier did not include a working camera focus driver in time.

Download thesis report
References
[1] Paul Viola and Michael J. Jones, 2001. Rapid object detection using a boosted cascade of simple features. http://www.hpl.hp.com/techreports/Compaq-DEC/CRL-2001-1.pdf