Practical Analysis of Optimized Ray-Triangle Intersection
Tomas Möller
Department of Computer
Engineering, Chalmers University of Technology, Sweden.
Introduction
Being a sucker for fast intersection tests, I just had
to try to optimize Trumbore's and my
ray-triangle intersector presented in
journal of graphics tools (JGT)
in 1997. Eric Haines
and I turned this (and some other optimizations
for the 2D case) into a little article
for Dr. Dobb's Journal. However, there was not space enough to
discuss all details, therefore this page exists.
First of all, I thought that it would be interesting to
see what happens with the intersection time as the number of hits increases from
0% to 100%. Second, as we said in our JGT article, the division
(after all, the division is pretty expensive, which is why we care
about it)
might be pushed away later in the code, by doing different
tests depending on the sign of the determinant. So, I implemented
this, and I believe that the code is even cleaner now (for example,
just take away the "else if" and you have a test for backface culling)
Third, I tried alot of different ways to order the computations in
the code, and finally settled on three different versions:
1) Having the divide at the end.
2) Having the divide early in the code.
3) Having the divide early in the code plus move a cross product
out from the "if-else if"-case.
(Version number 0 is simply the original JGT code).
The code for these four versions is available below.
I run my test program (compiled with "gcc -O2") on three different computers: an SGI Octane
with an R10K 175 MHz, a Sun UltraSPARC-IIi 333 MHz, and on
a Linux PC with a Pentium III 700 MHz. To make the test and the timings
reasonable (at least in some ways), I first randomized 1000 different
ray-triangle pairs and put these in a list. Then I started the clock
for the first optimization, and run through the list 10,000 times, and
then stopped the clock. Doing it this way, I think I avoid branch prediction
performance hits, which I may get if I repeat the same test for one ray-triangle
pair 10,000 times in a row (and then the next pair, and so on).
All this was done for all four versions of the code.
Code:
raytri.c: the code for all four different
version of the ray-triangle intersection routine.
Diagrams and discussion:
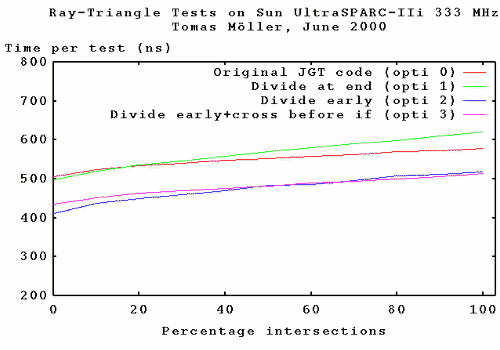
For this particular UltraSPARC (from Sun), it is obvious that the divide
instruction should be placed early in the code, and that thus, Sun
are pretty good at issuing instructions in parallel, i.e., starting
the divide instruction and then issuing other instructions in parallel
while the division is being computed. Then, when the result from the division
is needed, the result may already be computed (or at least close to being
computed).
For this CPU, I'd probably
choose optimization 2, but optimization 3 has similar performance.
Optimization 2 is about 12-23% faster for this test (and it's faster
the fewer intersections as one can expect) than the original jgt code.
Also, note that optimization 1 is almost always the slowest
(and not the original JGT code).
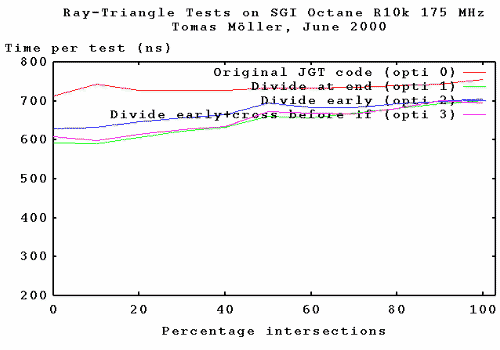
This was the slowest CPU I tried it on, and if I were to choose
one routine for this CPU, I would go with number 1 (which was slowest on
the UltraSPARC). It's interesting to see that there really isn't that
much of a difference between having the division early (optimization 2,3)
or late (optimization 1). Optimization 1 was about 7-20% faster than the original
jgt code.
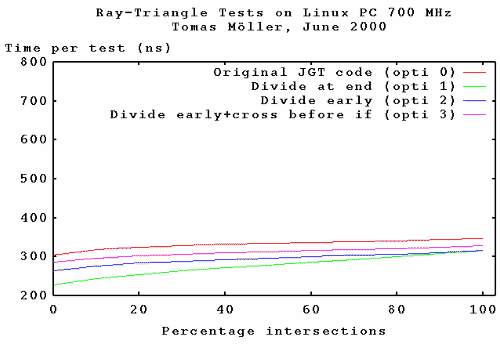
For the Pentium III, optimization 1 is the way to go. This
was not, however, what I expected. I thought that the Pentium III
would issue the division in parallel, but it looks like it does not (at least
not very well).
Optimization 1 is 10-33% faster than the original jgt code.
Last update by Tomas Möller on June 15, 2000