Un système de dialogue oral guidé pour la génération de comptes rendus médicaux
Frédéric CAZENAVE, Pierre-Olivier EL GUEDJ, Christophe GODÉREAUX et Pierre NUGUES
Institut des Sciences de la Matière et du Rayonnement
Laiac
6, boulevard du Maréchal Juin
14050 CAEN
Téléphone : 31-45-27-22 – Télécopie : 31-45-27-60
Courrier électronique :
pnugues@l2i.ismra.fr
Résumé
Nous décrivons l’architecture et l’implantation d’un prototype de dialogue oral. Ce prototype comporte un dispositif de reconnaissance vocale du commerce ainsi qu’un autre de synthèse. Il comprend des modules syntaxique et sémantique et permet la dictée de comptes rendus médicaux. Il génère automatiquement le document correspondant. Le système se compose d’un noyau-objet pour représenter les concepts linguistiques et médicaux; d’un analyseur syntaxique adapté à la langue orale; d’un analyseur sémantique gérant les entités médicales. L’analyseur syntaxique accepte les formes interrogatives et répond à certaines questions. Le système synthétise oralement des messages pour avertir l’utilisateur des erreurs ou pour fournir des réponses.
Mots-clés
:Dialogue oral, interfaces vocales, langue naturelle, système de dictée et de questionnement, applications médicales.
Summary
We describe the architecture and the implementation of an oral dialogue prototype. This prototype includes a voice recognition device together with a speech synthesizer. It features syntactic and semantic modules. It enables the dictation of medical reports and automatically creates the corresponding document. The system consist in an object oriented kernel to represent linguistic and medical concepts; a syntactic parser dealing with spoken natural language; a semantic analyzer handling the medical entities. The syntactic parse accepts interrogative forms and answer certain questions. The system synthesizes spoken messages to warn the user of errors or to provide an answer.
Keywords:
Oral dialogue, speech interfaces, natural language, dictation and querying systems, medical applications.
1 Introduction
Les systèmes de dictée orale permettent la génération automatique de textes écrits. De tels systèmes reposent sur des techniques de traitement de la parole et de la langue : la reconnaissance vocale, l’analyse syntaxique et sémantique, ainsi que le dialogue oral [Kurzweil 90, Pierrel 87]. Certains travaux de linguistique se sont spécifiquement intéressé au domaine médical [Bonnet 80, Baud 92, Cavazza 92]. D’autres systèmes combinent le traitement du langage médical et la dictée orale [Brunessaux 90, Kurzweil AI 90] pour permettre à des médecins de saisir leurs comptes rendus directement au micro d’un ordinateur.
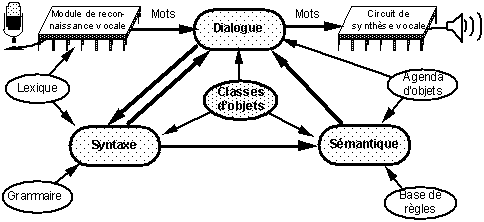
Le système de dictée médicale que nous décrivons, DictaMed, [Nugues 92, Nugues 93:1, Nugues 93:2], utilise un dispositif de reconnaissance vocale de mots isolés disponible sur le marché ainsi qu’un circuit de synthèse de parole. Il s’appuie sur une architecture modulaire dont les éléments ont pour tâche de gérer le dialogue, l’analyse syntaxique ainsi que l’analyse sémantique (Fig. 1). L’ensemble s’intègre dans un environnement graphique qui permet les commandes au clavier ou à la souris, et comporte des fenêtres graphiques de messages pour guider l’utilisateur.
En comparaison avec d’autres systèmes de dictée, DictaMed a la capacité d’interagir oralement avec l’utilisateur. L’analyseur syntaxique, notamment, accepte les formes interrogatives et, grâce à l’analyseur sémantique, DictaMed peut répondre à certaines questions concernant des entités précédemment décrites. Pour ceci, l’analyseur sémantique détermine les objets et les attributs sur lesquels porte une question et recherche les valeurs de ces attributs. L’interface de dialogue pilote alors la synthèse des messages audios de réponses à la question.
2 La représentation des objets
Un noyau–objet forme le cœur du système et permet de décrire toutes les entités linguistiques et sémantiques. Ces dernières correspondent ici à des concepts médicaux.
Nous avons implanté ce langage à objets au–dessus du Prolog. Il se fonde sur un formalisme proposé par Stabler, [Stabler 86], que nous avons étendu de manière significative. Ce langage permet la création de classes avec des variables et des méthodes, ainsi que d’objets correspondant à des instances des classes. Les classes et les objets appartiennent à une hiérarchie et héritent des variables et des méthodes de leurs super classes. On active les méthodes grâce à un mécanisme d’envoi de messages.
Les classes syntaxiques correspondent à des catégories de mots et de syntagmes. Pour chaque phrase énoncée, par exemple, un objet (une instance) de la classe " Phrase " est créé. La classe " Phrase " contient notamment les variables " groupe nominal sujet ", " groupe verbal " et " compléments ". L’analyse syntaxique de la phrase crée des objets conformes à ces catégories qu’on affecte aux variables correspondantes de l’objet " Phrase ". La variable : " groupe nominal sujet " contiendra ainsi un objet de la classe " Groupe nominal ". Parmi les variables de cette dernière classe figurent notamment : le déterminant, la liste des adjectifs, le nom, le genre et le nombre. On leur affecte les mots ou les caractéristiques correspondants du syntagme analysé.
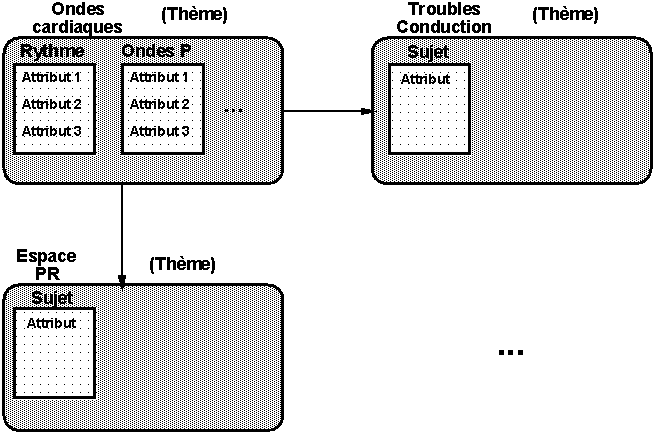
Les classes sémantiques représentent les entités médicales et la structure du compte rendu d’analyse. Nous avons limité le domaine des analyses aux comptes rendus de Holter tensionnels et nous avons déterminé les classes sémantiques en collaboration avec des médecins pratiquant ces analyses et dictant ce type de comptes rendus. Nous avons organisé les classes sémantiques en " Thèmes ", " Sujets " et " Attributs " (Fig. 2).
Les " Thèmes " correspondent aux divisions principales d’un compte rendu. Un thème correspondrait, sur un document écrit, à un paragraphe. Pendant la dictée, un automate pilote les transitions d’un thème à un autre. Des règles complètent cet automate et déterminent si les transitions sont licites ou non. Parmi les variables constituant un thème, il y a notamment : les messages d’erreur et d’aide, ainsi que l’agenda des thèmes suivants possibles.
À l’intérieur d’un thème particulier, les " Sujets ", propres à chaque thème, représentent les concepts que l’utilisateur peut mentionner et décrire. Par exemple, le " Rythme cardiaque " est un " Sujet " qui appartient au thème des " Ondes cardiaques ". Parmi les variables qui constituent un sujet, on trouve notamment les " autres sujets " qui pourront suivre sa description et qu’on ajoutera à l’agenda du thème. Certains sujets doivent être mentionnés, d’autres sont optionnels. Le médecin peut aborder les différents sujets de l’agenda d’un thème dans n’importe quel ordre, mais il doit traiter tous les sujets obligatoires avant de pouvoir passer à un autre thème. Le système définit dynamiquement ces sujets obligatoires en ajoutant les " autres sujets " à l’agenda et en considérant le statut des " Attributs ". Le sujet Rythme se représente par exemple par :
rythme(
[descripteur, rythme],
[attributs, [vitesse, caractère, équilibre],
[autresSujets, [troublesDuRythme, ondesP,
fréquence, électroEntraîné]])
On décrit un " Sujet " par des objets " Attributs " correspondants à des groupes d’adjectifs associés à ce sujet. Lors de la conception, nous avons distingué les adjectifs pouvant être attributs du sujet de ceux qui ne peuvent être qu’épithètes. Les objets " Attributs " correspondent aux adjectifs de la première catégorie, c’est-à-dire pouvant être attributs du sujet. Par exemple, " Vitesse " est un " Attribut " du " Sujet " " Rythme cardiaque ". En effet, la vitesse peut être lente ou rapide. En revanche, " le rythme est cardiaque " ne correspond pas à une phrase sensée dans les analyses qui nous concernent. Les variables constituant les attributs comprennent la valeur qu’on leur donne par la dictée et des propriétés telles que le domaine des valeurs possibles.
De plus, les sujets et les attributs comprennent une variable " liste de contraintes " que la présence d’un sujet ou la valeur spécifique d’un attribut peut imposer à d’autres sujets ou attributs. On peut aussi inclure des vérifications heuristiques par l’intermédiaire de règles qui se déclenchent lors de la mention d’un sujet ou de la description d’un attribut. Ces règles s’activent comme des réflexes d’objets.
L’attribut caractère se représente par exemple par :
caractère(
[descripteur, caractère du rythme],
[messageCourant, "le caractère du rythme est
enregistré"],
[messageErreur, rythme sinusal ou irrégulier],
[domaineDéfinition, [sinusal, irrégulier]],
[contraintes,
[[sinusal,
[interdit, troubles du rythme],
[obligatoire, fréquence]]]],
[règle, règleCaractère],
[statut, obligatoire]])
3 L’analyse syntaxique
Nous avons conçu l’analyseur syntaxique pour accepter un sous ensemble oral du français. Il analyse les phrases prononcées et vérifie leur rectitude grammaticale. Il utilise des règles de grammaire DCG (Definite Clause Grammar) [Pereira 80, Gazdar 91] étendues. Il accepte des formes affirmatives – actives ou passives –, négatives et interrogatives. L’analyseur reçoit une séquence de mots provenant du dispositif de reconnaissance vocale. Il en crée des objets linguistiques structurés simultanément avec la dictée. Ces objets seraient éventuellement retirés si l’analyse se trouvait ultérieurement en échec.
Des règles de récriture contextuelles constituent la grammaire. Ses unités syntaxiques de base sont :
• les groupes nominaux sujets,
• les groupes verbaux et
• les " compléments ".
Parmi les " compléments ", nous avons regroupé les groupes d’attributs du sujet, les compléments d’objets directs et plusieurs types de groupes prépositionnels. La prise en compte du contexte permet de restreindre le nombre de structures possibles lors de l’analyse syntaxique. Grâce à ceci, nous vérifions notamment la présence (resp. l’absence) de compléments obligatoires (resp. interdits) que certains verbes peuvent requérir (resp. exclure). On indique ces compléments comme des arguments dans la structure de chacun des verbes du lexique.
La structure simplifiée d’une phrase s’exprime par la règle suivante :
phrase(Obj) --> (1)
groupeNominal(Nobj), (2)
groupeVerbal(Vobj, O, I), (3)
compléments(Cobj, O, I), (4)
{créeObjet(phrase, Obj), (5)
affecte(Obj, groupeNominalSujet, Nobj), (6)
affecte(Obj, groupeVerbal, Vobj), (7)
affecte(Obj, compléments, Cobj)}. (8)
Table 1 : Structure syntaxique simplifiée d’une phrase
Cette règle signifie qu’une phrase (1) se compose d’un groupe nominal (2), d’un groupe verbal (3) et d’un ou plusieurs compléments (4); pour chaque phrase, un objet phrase :
Obj est créé (5), dont on affecte la variable groupeNominalSujet (6) avec l’objet groupe nominal : Nobj, créé par (2); groupeVerbal (7) et compléments (8) sont affectés d’une manière semblable. Les variables O et I de (3) correspondent aux contraintes d’obligation (O) et d’interdiction (I) appliquées à compléments (4).Une analyse utilisant une grammaire DCG ordinaire n’est pas réalisable avec une entrée vocale car elle ne réussit qu’avec une phrase correcte et complète. Pour accepter une suite continue de mots en provenance du circuit de reconnaissance, nous avons étendu la grammaire DCG en lui ajoutant un prédicat "
geler ". Ce prédicat analyse une liste de mots représentant une phrase incomplète. Quand il atteint la fin de la liste, le prédicat se bloque en lecture jusqu’à ce qu’il reçoive un mot nouveau. À la réception de ce mot, " geler " relance l’analyse et l’ajoute à la phrase en cours ou éventuellement le rejette si il n’est pas correct du point de vue syntaxique. Le prédicat " geler " est compatible avec le formalisme DCG et on doit l’insérer avant chaque symbole terminal dans la partie droite des règles.Par ailleurs, on pallie certaines ambiguïtés de reconnaissance pour des homonymes ou des mots de prononciation voisine en tenant compte de leur phonétique lors de l’analyse syntaxique. Pour ceci, le lexique intègre la transcription phonétique de chaque mot qui le compose.
De plus, pour rendre l’écriture des règles DCG plus facile et plus compacte, nous avons ajouté le prédicat "
facultatif ". Ce prédicat, compatible avec le formalisme DCG, permet de rendre optionnels certains constituants d’une règle de grammaire. Ainsi, la règle :groupeNominal --> (1)
déterminant, (2)
facultatif(adjectif), (3)
nom. (4)
signifie qu’un groupe nominal (1) est composé d’un déterminant obligatoire (2), suivi éventuellement d’un adjectif (3) puis d’un nom obligatoire (4).
Enfin, le médecin termine chacune de ses phrases ou de ses syntagmes en prononçant le mot " point ". Ce mot point permet de connaître sans ambiguïté la fin d’un groupe de mots pensé comme une entité indépendante par le locuteur. En combinaison avec le prédicat
facultatif, il rend plus facile le codage et le traitement des groupes nominaux incomplets.4 Les règles syntaxiques
4.1 Le lexique
Les mots constituant le lexique sont typés par leur catégorie syntaxique. Nous les avons définis par des prédicats de la forme générale suivante :
catégorie(mot, phonétique, genre, nombre), tel que par exemple nom(rythme, ritm, masc, sing). Certaines catégories, comme les prépositions, n’ont ni genre, ni nombre; dans ce cas, nous avons limité leurs arguments aux attributs : mot et phonétique.Nous avons utilisé les catégories syntaxiques : déterminants, noms, conjonctions (divisées en différents types), prépositions (divisées aussi en différents types), adjectifs et adverbes. Les verbes – quant à eux – subissent un traitement particulier du fait de leurs variations morphologiques. Nous les avons représentés par les prédicats :
•
•
infinitif(mot, phonétique, complémentsObligatoires, complémentsInterdits, auxiliaireDeConjugaison),qui correspondent respectivement aux formes conjuguées et à la forme infinitive. Par exemple :
•
•
infinitif(exister, egziste, [complémentObjetDirect], [complémentAccompagnement, attributDuSujet], avoir).La combinaison de ces deux prédicats permet de réduire la taille de la base de données en concentrant les informations de contexte – portant notamment sur les compléments – dans la forme à l’infinitif.
Pour faciliter l’analyse du groupe verbal, nous avons aussi ajouté les prédicats :
•
•
participePassé(mot, phonétique, genre, nombre, infinitif).4.2 Les catégories syntagmatiques
Les catégories syntagmatiques composant la phrase sont les groupes sujets, les groupes verbaux et les compléments.
Les groupes sujets correspondent soit à un groupe nominal – ou à une conjonction de groupes nominaux – soit à un pronom personnel. Ceci se traduit, d’une manière simplifiée, par les règles suivantes :
groupeSujet -->
groupeNominal.
groupeSujet -->
[X],
pronom(X).
Nous avons représenté les groupes nominaux par la règle de base suivante :
groupeNominal -->
déterminant,
facultatif(listeAdjectifs),
nom,
facultatif(listeAdjectifs),
facultatif(complémentDuNom),
facultatif(complAccompagnement),
facultatif(propRelative).
Le groupe verbal correspond à des formes actives et passives de la phrase. Il peut prendre les formes simplifiées suivantes :
1.
groupeVerbal -->verbe.
où
verbe est un auxiliaire ou bien un verbe conjugué à un temps simple et dont la voix est active.2.
groupeVerbal -->auxiliaireAvoir,
participePassé
.qui correspond à une voix active passée, le verbe se conjuguant avec l’auxiliaire " avoir ".
3.
groupeVerbal -->auxiliaireÊtre,
participePassé
.est une forme similaire à la précédente, le verbe se conjugant avec l’auxiliaire " être ".
4.
groupeVerbal -->auxiliaireÊtre,
participePassé
.qui correspond à une voix passive d’un temps simple. Le verbe se conjugue avec l’auxiliaire " avoir ".
5.
groupeVerbal -->auxiliaireAvoir,
[été],
participePassé.
enfin, qui correspond à une voix passive d’un temps composé.
Les classes de "
compléments " se divisent en attributs du sujet, en compléments d’objet direct et en syntagmes prépositionnels. Ces deux dernières classes héritent de la classe " groupeNominal "; les groupes prépositionnels étant regroupés en sous-classes définies par la préposition qui les introduit. Ainsi, un complément d’accompagnement est un groupe nominal précédé de la préposition " avec " ou bien de la préposition " à ".4.3 Les formes de la phrase
La forme fondamentale des phrases lors de la dictée de comptes rendus est l’affirmation. Cette forme correspond à la règle de la table 1; elle peut être active ou passive. Les affirmations, à l’exception des mots de commande de rédaction, tels que corriger, effacer, terminer,… sont destinées à être retranscrites dans le texte final.
Le système est aussi susceptible d’analyser certaines formes interrogatives telles que : " Comment est le rythme? " ou bien " Comment est la vitesse du rythme? " ou bien encore " Est-ce que le rythme est sinusal? ". Après avoir déterminé la structure syntaxique, il interprétera ces formes et tentera de répondre, grâce à l’analyseur sémantique et en considérant la base des objets créés, aux questions correspondantes. L’analyse de la forme interrogative est effectuée par la grammaire simplifiée suivante :
phrase -->
motInterrogatif,
groupeVerbal,
groupeSujet,
compléments.
phrase -->
[estCeQue],
groupeSujet,
groupeVerbal,
compléments.
motInterrogatif -->
[X].
où
X est un adjectif interrogatif tel que "quel", "quelle", ... ou bien un adverbe interrogatif tel que "comment".5 L’analyse sémantique
Une fois la phrase transformée en objets linguistiques et la catégorie de chaque mot déterminée, l’analyseur sémantique établit des relations d’association entre les mots de la phrase. Il détermine ainsi si la phrase a un sens en contrôlant que le sujet fait bien partie du thème courant et en réalisant le bon appariement du sujet et de ses attributs. Enfin, il crée les objets médicaux correspondants.
Le prédicat "
associations(ObjetPhrase, Nom, ListeAdjectifs) " établit les relations entre les mots en recherchant, pour chaque nom Nom de l’objet phrase ObjetPhrase, la liste d’adjectifs associés : ListeAdjectifs. Il considère le cas trivial où le nom et les adjectifs sont dans le même syntagme. Il examine aussi les groupes d’attributs du sujet et, récursivement, les propositions relatives. " associations " détecte ainsi les objets " Sujets " mentionnés dans une phrase.Un prédicat supplémentaire "
complémentNom(ObjetPhrase, Nom, ComplémentDuNom) " permet d’associer pour une phrase ObjetPhrase, le complément du nom ComplémentDuNom, d’un groupe nominal Nom. Il permet de distinguer certains objets " Thèmes " ou " Sujets " et de différencier, par exemple l’objet " Troubles du rythme " d’avec l’objet " Troubles de la conduction ".Dans le cas où le sujet de la phrase est un pronom tel que " il " ou " elle ", le système résout la référence en identifiant ce pronom au dernier objet créé de même genre. Ainsi dans le cas des deux phrases suivantes : " Le rythme est sinusal. " " Il est lent. ", le pronom " il " est assimilé à l’objet rythme précédemment créé. On affecte son attribut vitesse avec la valeur " lent ". Cette résolution permet d’orthographier correctement les pluriels des pronoms en faisant correspondre au nombre du pronom, le nombre de l’objet auquel il se réfère.
Lorsque les objets médicaux sont créés, des vérifications sont effectuées, notamment sur la cohérence entre les différentes valeurs des objets attributs. On implante ces vérifications par l’intermédiaire de la variable
listeContraintes de ces objets qui décrit des contraintes de la forme :(valeur 1, typeDeContrainte, [sujetDestination, attributDestination, valeur 2])
. Le type de la contrainte peut être : obligatoire, optionnel ou interdit, et signifie, par exemple, que si la " valeur 1 " est donnée, elle interdit la " valeur 2 " à l’attribut attributDestination du sujet sujetDestination. Une fois la valeur d’un attribut donnée, les contraintes correspondantes sont propagées grâce à un système TMS de maintien de la vérité (Truth Maintenance System) [Doyle 79]. Si la valeur est retirée, les contraintes correspondantes sont aussi retirées. Des contraintes peuvent être propagées de la même manière aux sujets pour rendre leur mention interdite ou obligatoire.Le système détecte un conflit quand un objet attribut est créé avec une valeur interdite ou quand une valeur interdite est transmise à un sujet existant. Dans ce cas un message est émis. L’utilisateur peut cependant ignorer l’avertissement et l’objet correspondant sera alors créé.
Le système peut répondre à certaines questions. Ces questions, de cinq types possibles, doivent porter sur un sujet, sur les attributs d’un sujet ou bien sur les valeurs possibles à donner à un attribut. (Table 2, colonne de gauche)
Pour répondre aux questions, le système analysera les objets créés précédemment. Si les objets n’existent pas (si ils n’ont pas été créés précédemment), le système signalera qu’il ne peut répondre. Si ces objets existent, l’analyseur construira la réponse et la synthétisera vocalement. (Table 2, colonne de droite)
6 Les interfaces graphique et sonore
Les messages émis par le système combinent la synthèse de parole et de sons et une interface graphique. D’autres auteurs ont étudié cette fusion [Battani 91]. Les messages sonores de DictaMed correspondent à des notifications, à des questions, à des réponses, ainsi qu’à une aide de dictée pour un utilisateur novice au système.
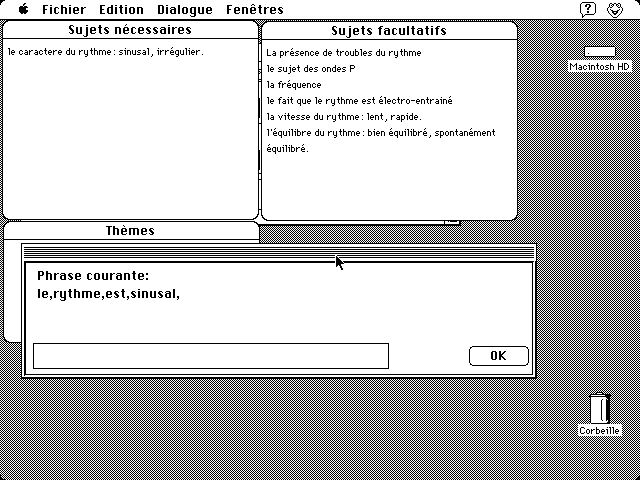
L’interface graphique (Fig. 3) fournit une aide par la liste des sujets et des thèmes qui peuvent être abordés. À l’intérieur du thème courant, deux fenêtres : "
Sujets nécessaires " et " Sujets facultatifs " spécifient les sujets obligatoires et optionnels ainsi que les valeurs permises de leurs attributs. Ces fenêtres sont mises à jour simultanément avec la création des nouveaux objets et la propagation de nouvelles contraintes. Une fois que l’utilisateur a décrit tous les objets obligatoires, les thèmes suivants possibles apparaissent dans la fenêtre " Thèmes ".Alors que l’interface graphique fournit une aide assez détaillée, l’interface à synthèse vocale permet au médecin de se concentrer sur son analyse sans avoir à regarder l’écran. On utilise les messages vocaux pour avertir ou pour questionner le médecin quand une erreur ou un conflit se produit. Ces messages d’erreur tentent de gérer le compromis suivant : être aussi explicatifs que possible, mais également, aussi courts que possible car les messages sonores tendent à être lassant à la longue.
|
Questions de l’utilisateur |
Réponses synthétisées par le système |
|
" Est-ce que tel attribut de tel sujet a telle valeur? ", par exemple, " Est-ce que la vitesse du rythme est rapide? " |
Oui ou non, en fonction de la valeur de l’attribut déjà dicté et de la valeur demandée par la question |
|
" Est-ce que tel sujet a telle valeur? ", par exemple, " Est-ce que le rythme est rapide? " |
Oui ou non, si la valeur mentionnée dans la question apparaît dans les valeurs des attributs instanciés |
|
" Comment est tel attribut de tel sujet? ", par exemple, " Comment est la vitesse du rythme? " |
La valeur de l’attribut spécifique demandé, en vérifiant qu’il existe bien |
|
" Comment est tel sujet? ", par exemple : " Comment est le rythme? " |
La valeur de tous les attributs instanciés du sujet (par exemple du rythme) |
|
" Quels sont les valeurs possibles de tel sujet? ", par exemple, " Quelles sont les valeurs possibles du rythme? " |
Les valeurs de la variable " valeursPossibles " des attributs du sujet en question |
Pour notifier une erreur, le système émet différentes coupures sonores puis indique là où l’erreur s’est produite, par exemple, dans le cas d’une erreur syntaxique, en répétant la phrase courante privée du mot fautif. Ce type d’erreur est principalement dû aux confusions du circuit de reconnaissance vocale. L’interface peut aussi fournir une fenêtre d’alerte ainsi qu’une explication optionnelle grâce à une fenêtre de texte.
7 La génération de texte
La génération de texte a pour objet de notifier à l’utilisateur les erreurs sémantiques lors de la dictée ainsi qu’à produire le document écrit à la fin.
Les erreurs sémantiques correspondent à :
•
•
la description d’un attribut par plusieurs valeurs, par exemple, quand on affirme que le rythme est rapide puis qu’il est lent.Dans le cas d’erreurs sémantiques, un message prototype est émis qui demande la confirmation ou l’annulation de l’affirmation. Ce message indique à l’utilisateur les attributs et les valeurs en jeu.
La génération de texte du compte rendu à lieu à la fin de l’analyse. Cette génération permet de mettre en forme le texte et d’inclure automatiquement au document imprimé un en-tête, la date, des références, le nom du praticien, etc.
La génération du compte rendu reprend les formules originelles du médecin. Elle tient compte des modifications et effectue certaines vérifications sur la cohérence globale du texte. Ceci se réalise en deux étapes :
1.
Lors d’une modification de la valeur d’un attribut, on substitue la nouvelle valeur à l’ancienne dans la phrase d’origine. Par exemple, à la suite de l’affirmation " le rythme est lent " puis de la contradiction " le rythme est rapide ", " rapide " remplace " lent " dans la première phrase. On ajoute cependant à cette étape la nouvelle phrase dans le compte rendu. Le résultat est un texte comportant des phrases redondantes.2
. On élimine ensuite les formules redondantes en vérifiant si chacune des phrases n’est pas comprise sémantiquement dans une autre. Pour ceci, on considère les phrases affirmatives de même temps et de même verbe et on applique le prédicat associations(ObjetPhrase, Nom, ListeAdjectifs). Les phrases en question correspondent à celles dont la liste d’adjectifs associés à un nom est comprise dans une autre phrase.Ces vérifications n’éliminent pas toutes les redondances. Elles laissent celles correspondant à des listes d’adjectifs ne s’incluant pas l’une dans l’autre. Elles permettent cependant d’en nettoyer le texte d’une partie importante.
8 Implantation et exemple de dialogue
Nous avons développé un prototype de ce système sur un ordinateur Macintosh II SI. Le dispositif de reconnaissance vocale est un module externe Voice Navigator II [Articulate 90] relié par un câble SCSI. Ce système est mono-locuteur et reconnaît des mots isolés. Il impose un apprentissage préalable des mots. Avant de pouvoir s’en servir, l’utilisateur devra répéter chaque mot du lexique environ 3 fois. Un logiciel résident pilote Voice Navigator II et opère simultanément avec le programme de dialogue et de traitement linguistique. Les mots reconnus sont envoyés dans le tampon de lecture de l’ordinateur. Ce tampon est lu par la boucle principale du programme de dialogue. La synthèse vocale utilise des mots préenregistrés ainsi que l’interface sonore intégrée dans les ordinateurs Macintosh. Le logiciel a été écrit en AAIS Prolog 2.0 et totalise plus de 8.000 lignes (400 prédicats). Jusqu’à présent, cette quantité de code n’a pas dépassé les capacités de l’ordinateur. Le traitement linguistique est suffisamment rapide pour qu’il donne à l’utilisateur l’impression d’une prise en compte, suivie éventuellement d’une réaction, instantanée.
Le prototype a été conçu pour des analyses de Holter tensionnel pour lesquelles nous avons développé une syntaxe recouvrant un sous ensemble du français ainsi que la sémantique associée; le lexique compte 180 mots.
Nous avons présenté DictaMed au 3ème congrès du Collège national des cardiologues français. À cette occasion, il a fait l’objet de démonstrations devant des médecins et il a reçu un accueil très favorable.
À titre d’exemple, on peut mener des dialogues tels que celui qui suit pour construire un compte rendu. Cette dictée n’est pas réaliste du point de vue médical; elle illustre cependant les capacités syntaxiques et d’interaction.
|
Affirmations ou questions de l’utilisateur |
Réponses de DictaMed |
|
Le rythme est sinusal. |
Prêt |
|
Il est lent. |
Bien |
|
Il est rapide. |
Bip, vous avez affirmé que le rythme était lent, confirmez-vous ce changement de valeur? |
|
Oui |
|
|
DictaMed Quelle est la vitesse du rythme? |
Elle est rapide |
|
DictaMed Est-ce que le rythme est sinusal? |
Oui |
|
La fréquence moyenne et la fréquence mini sont de 52. |
Bien |
|
DictaMed Comment sont la fréquence moyenne et la fréquence mini? |
La fréquence moyenne et la fréquence mini sont de 52. |
|
DictaMed Comment sont le rythme , la fréquence moyenne et la fréquence maxi? |
La fréquence moyenne est de 52. Pas de réponse pour la fréquence maxi. |
|
La fréquence maxi est de 110. |
Prêt |
|
Un rythme bien équilibré a été noté. |
Bien |
|
Les ondes P sont notées. |
Je suis prêt |
|
Elles sont bifides et peu visibles. |
Bien |
|
DictaMed Comment sont les ondes P et le rythme? |
Les ondes P sont bifides et peu visibles. Le rythme est rapide et sinusal. |
|
DictaMed Est-ce que la fréquence maxi est de 110? |
Oui |
DictaMed a été évalué par l’ANVAR et a bénéficié d’un contrat de sa part.
9 Discussion et conclusion
Nous avons décrit et implanté un prototype de machine à dicter destinée à un usage médical. Nous avons détaillé certaines de ses caractéristiques concernant notamment les analyseurs syntaxiques et sémantiques, ainsi que la combinaison des interfaces graphique et sonore. Dans nos choix, nous avons cherché à privilégier la simplicité aux dépens de la complexité.
Au cours des essais, nous avons remarqué que l’" acceptabilité " de ce type de systèmes dépendait largement de la qualité de la reconnaissance vocale. Cette reconnaissance n’est pas encore parfaite et son taux peut varier de manière considérable en fonction du type de micro, par exemple, ou bien de sa position par rapport à la bouche du locuteur. Cependant, des dispositifs de reconnaissance apparaissent régulièrement avec une qualité qui s’améliore de manière constante.
Des efforts sont en cours ou en projet :
• pour étendre l’interactivité et augmenter les capacités de dialogue;
• pour rendre la syntaxe plus robuste aux mots manquants [El Guedj 93];
• pour améliorer la sémantique et enfin
• pour tester le système dans un contexte opérationnel.
Nous espérons que ces efforts fourniront une aide utile à la médecine.
Références
[Articulate 90] Voice Navigator Owner’s Guide, Articulate Systems, Cambridge, États-Unis, 1990.
[Battani 91], G. Battani, R. Pasero, P. Sabatier, Le projet ILLICO, Interfaces en langage naturel et graphique, Conférence Génie linguistique, Versailles, janvier 1991.
[Baud 92], R.H. Baud, A.M. Rassinoux, et J.R. Scherrer, Natural language processing and semantical representation of medical text, Methods of Information in Medicine, 31:117—125, 1992.
[Bonnet 80], A. Bonnet, Analyses de textes au moyen d’une grammaire sémantique et de schémas, Application à la compréhension de résumé médicaux en langage naturel, Thèse d’État, Université Pierre-et-Marie-Curie, 1980.
[Brunessaux 90] L. Brunessaux, P. Mariot, H. Mahé, J.-M. Pierrel, A. Wattiez, G. Willemain, Satic, un Système de dialogue oral pour l'Assistance Technique à l'Intervention Chirurgicale, Actes de la conférence sur les systèmes experts, EC2, Avignon, 1990.
[Cavazza 92], M. Cavazza, L. Doré et P. Zweigenbaum, Model-Based Natural Language Understanding in Medicine, MEDINFO 92, Genève, pp.1356-1361, septembre 1992.
[Doyle 79] J. Doyle, A Truth Maintenance System, Artificial Intelligence, vol. 12, 1979.
[El Guedj 93], P.-O. El Guedj et P. Nugues, A Chart Parser Making Assumptions about Missing Words, soumis.
[Gazdar 91] G. Gazdar and C. Mellish, Natural Language Processing in Prolog, Addison Wesley, 1991.
[Kurzweil 90] R. Kurzweil, The Age of Intelligent Machines, MIT Press, 1990.
[Kurzweil AI 90], VoiceMED, Kurweil AI, Waltham, 1990.
[Nugues 92] P. Nugues, P.O. ElGuedj, F. Cazenave, and B. de Ferrière, Issues in the Design of a Voice Man Machine Dialogue System Generating Written Medical Reports, Proc. of the Annual Int. Conf. IEEE/EMBS, Vol. 14, 1992.
[Nugues 93:1], P. Nugues, C. Godéreaux, P.-O. El Guedj, et F. Cazenave, Système de dialogue homme-machine pour la génération de comptes rendus médicaux, Innovation et Technologie en Biologie et Médecine, vol. 14, no 4, 1993.
[Nugues 93:2] P. Nugues, C. Godéreaux, P.O. El Guedj and F. Cazenave, Question Answering in an Oral Dialogue System, Proc. of the Annual International Conference of the IEEE/EMBS, Vol. 15, 1993.
[Pereira 80] F.C. Pereira and D.H. Warren, Definite Clause Grammars for Natural Language Analysis, Artificial Intelligence, Vol. 13, 1980.
[Pierrel 87] J.M. Pierrel, Dialogue oral homme-machine, Hermès, 1987.
[Stabler 86] Object Oriented Programming in Prolog, E.P. Stabler, AI Expert, Oct. 1986.