Detta är några frågor som jag fått dagarna före tentamen (jag skriver svaren på svenska, eftersom tentan kommer att ges på svenska).
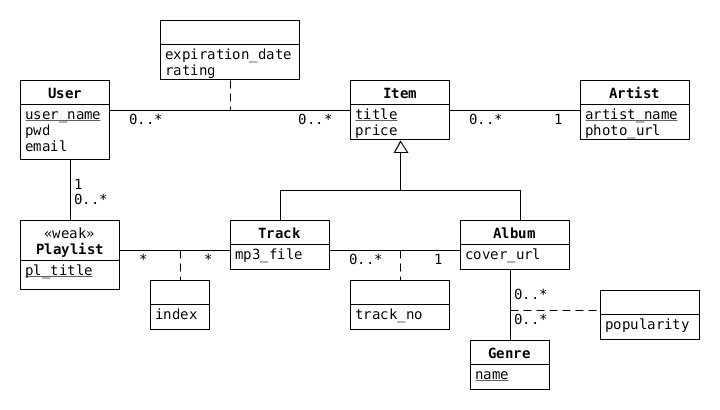
När vi under sista föreläsningen löste extentan från 2011-05-06 (länkar finns under "Lectures" på hemsidan) fick vi följande E/R-modell:
Här finns fyra (namnlösa) klasser som är kopplade till associationer med en streckad linje, som exempelvis mellan User och Item:
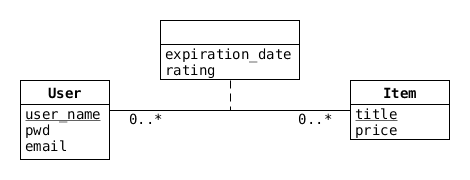
Figuren skall illustrera att det inte bara finns en koppling mellan användare och varor, för varje sådan koppling (inköp) finns dessutom ett utgångsdatum (expiration_date) och ett betyg (rating).
För att skilja en association som har en (eventuellt namnlös) klass kopplad till sig (som den mellan Playlist och Track ovan), från en vanlig association, har jag ibland lite slarvigt kallat dem för 'kvalificerade associationer' -- det är lite olyckligt att det på engelska finns en term qualified association som betecknar något som är besläktat, men inte riktigt samma sak. Den tekniska UML-termen för kopplingen mellan Playlist och Track är association class (associationsklass), men personligen tycker jag att det är synd att namnet sätter fokus på 'klassen' snarare än associationen (jag borde kanske ändå ha använt uttrycket associationsklass).
Hursomhelst, för en "many-to-many"-association som den mellan User och Item, behöver vi en ny relation, och vi lägger attributen expiration_date och rating i den (de kan inte rimligen finnas i vare sig User eller Item). Så vi introducerar en ny relation, exempelvis user_items, och får då:
users(user_name, pwd, email)
items(title, price)
user_items(user_name, title, expiration_date, rating)Vi kan illustrera det som i denna figur (där vi bara gett associationsklassen ett namn):
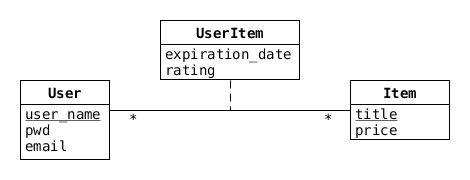
Observera nu att relationerna ovan är precis samma som vi skulle ha fått om vi istället för vår associationsklass (UserItem) hade introducerat UserItem som ett (vekt) entity-set mellan User och Item:
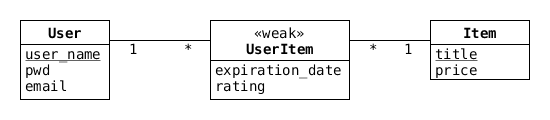
Så det spelar i praktiken ingen roll om ni väljer att använda associationsklasser för att beskriva associationer mellan entity-sets, eller om ni intoducerar nya entity-sets 'mellan' era gamla entity-sets.
Frågan gäller om man för relationer som
people(ssn, name, address)
addresses(street_address, zip_code, city)skall använda de 'naturliga' nycklar (business keys) som redan finns i modellen, i detta fall ssn för en person, street_address och zip_code för en adress, eller om man skall introducera särskilda nycklar (invented keys, eller surrogate keys), som i:
people(p_id, ssn, name, address)
addresses(a_id, street_address, zip_code, city)där p_id och a_id kan vara heltal som är unika för varje rad (en rimlig kompromiss här hade kanske varit att använda a_id för adresser, men att strunta i p_id och istället använda ssn som nyckel för people).
Somliga vill undvika 'invented keys' till varje pris, andra använder dem överallt, och det finns inget enkelt rätt eller fel -- det finns duktiga personer som har jobbat med databasutveckling i flera decennier, som står på vardera sidan i denna debatt.
En fördel med naturliga nycklar är att det är lätt att förstå de värden vi skickar in i våra 'queries', och att vi slipper att göra en massa extra 'joins' -- en nackdel är att det kan innebära att vi måste släpa runt 'stora' nycklar (som för addresses ovan), och att vi måste ändra på flera ställen om vi ändrar i en naturlig nyckel.
Jag väljer att ställa mig utanför debatten, och låter er själva komma fram till vad ni tycker känns bäst.