Christian Rahm
Examensarbete i datalogi
Juni 2001
Sammanfattning
Projektet handlar om att skapa ett lag av agenter som kan spela fotboll i RoboCups simulatorliga. På grund av den komplicerade miljön som omger agenterna, inkluderar projektet bitar från både realtidsprogrammering och Artificiell Intelligens. Inom realtidsprogrammering tar jag upp hanteringen av kommunikation med hjälp av process- och trådlösningar, och synkronisering mellan server och klient. Inom AI handlar min rapport om agentuppbyggnad, beslutsfattande, beteende och inlärning med ett neuralt nätverk. Ett lag uppbyggt av enkla beteende skapades. Efter detta skapades ännu ett lag, genom att ändra "sparka boll-beteendet" från ett enkelt beteende till ett självlärande beteende som lär sig under spelandets gång. Dessa lagen testades senare i två försök med sammanlagt 60 matcher och laget med bara enkla beteende fungerade bättre under de förutsättningarna som gällde.
Abstract
The project is about how to create a team of agents who can play soccer in the RoboCup simulated league. Because of the complicated environment that surrounds the agents, the project includes pieces from both realtime programming and Artificial Intelligence. In realtime programming I include the handling of communication with process- and threadssolution, and synchronisation between server and client. In the field of AI my rapport includes agentarchitecture, decisionmaking, behaviours and learning with a neural network. A team based on simple behaviours was created. After this a second team was created, by changing the kickballbehaviour from a simple behaviour to a selflearning behaviour that learns during the game. These teams where later tested in two experiments with a total of 60 matches and the team with the simple behaviour functioned better under the circumstances.
Innehållsförteckning
3.1 Soccerserverns modell av en fotbollsmatch
3.2 Informationen från Soccerservern
3.3 Spelarens agerande till Soccerservern
4 Synkronisering och signalmodeller
7 Beslutsfattningen och beteendena
8 Reinforcement learning och neurala nätverk
8.3 Modellen av världen runt agenten
C Utdrag från Soccerserver Manual Ver 5 [4]
Inom artificiell intelligens används agenter för att skapa lösningar på både mjukvaru- och hårdvaruproblem. Problemen spänner från robotar som löser problem i den riktiga världen till uträkningsproblem som agenten löser helt och hållet i den virtuella världen. Med hjälp av agenter försöker vi skapa problemlösare som agerar rationellt i sin miljö, vilkas agerande kan skilja sig från hur en människa själv skulle välja att lösa problemet. Forskare över hela världen experimenterar med olika arkitekturer för agentuppbyggnad som gör att agenterna ska bli så överskådliga som möjligt. Detta för att agenterna också ska bli enkla att bygga upp (programmera). Eftersom jag är intresserad av artificiell intelligens och agenter så valde jag detta examensarbete som gav mig möjligheten att skapa agenter i en komplex omvärld.
Syftet med detta examensarbete är att skapa agenter som spelar fotboll till RoboCups Simulatorliga och utvärdera dessa agenter. För att en agent ska kunna spela fotboll så måste agenten först hantera kommunikationen mellan Soccerservern och sig själv. Från Soccerservern får agenten sina indata från sina perceptorer (sinne). Agentens agerande skickas till Soccerservern som utför agerandena och uppdatera agentens omvärld. När agenten kan hantera kommunikationen mellan Soccerservern och sig själv, så är det dags att bestämma vad agenten ska göra i olika situationer. Detta görs genom att bygga in ett beslutsfattande i agenten. Man kan programmera beslutsfattandet till att bestämma ner till minsta agerande vad som ska göras, eller så kan man som i min implementation använda sig av beteende. Beslutsfattningen bestämmer då vilket beteende som ska användas och beteendet bestämmer vilket agerande som sänds till Soccerservern. Dessa beteende blir då byggstenarna som man använder för att bygga upp agentens agerande. Som slutkläm bestämde jag mig för att testa om ett beteende som lär sig under spelandets gång skulle fungera bättre än ett enkelt beteende som jag skapade först. Detta gjorde jag genom att göra ett självlärande neuralt nätverk som skulle bestämma hur agenten skulle sparka på bollen.
´´ RoboCup (The Robot World Cup Initiative) is an attempt to promote intelligent robotics research by providing a common task for evaluation of various theories, algorithms, and agent architectures.``
Citat ur artikeln: RoboCup: Today and tomorrow - What we have learned [1].
Översättning:
´´ RoboCup (Robot Världs Cup Initiativet) är ett försök till att främja intelligent robotforskning genom att bistå med ett standard problem för utvärdering av olika teorier, algoritmer, och agentarkitekturer.``
´´ En agent är bara något som uppfattar och agerar. ``[2]. En agent uppfattar sin miljö och med hjälp av vad han tror, gör agenten rationella val för att uppfylla sitt/sina mål. Vad agenten tror kan vara mer än vad han har uppfattat av sin miljö med sina sinnen. Enligt denna definition kan en agent vara en levande varelse, men i detta fall kommer vi att se agenterna som antingen program eller robotar som uppfattar och agerar i en miljö. Agentarkitekturen är den modell man använder för att bygga upp agenten. Man kan ha två olika agenter som är programmerade med utgång från samma arkitektur, men en av dessa kan fungera bättre än den andra beroende på deras skillnader i sinne eller sätt att agera. RoboCup har valt att ha fotboll som sitt standard problem. Detta på grund av fotbollens popularitet. RoboCups första världsmästerskap var 1997 och världsmästerskapet hålls årligen. Fyra världsmästerskap har spelats och den femte skall spelas den 2 till 10 augusti i Seattle.
Målet för RoboCup var 1998:
´´ By the mid-21st century, a team of autonomous humanoid robots shall beat the human World Cup champion team under the official regulations of FIFA.``
Citat ur artikeln: RoboCup: Today and tomorrow-What we have learned [1].
Översättning:
´´ På mitten av 20-hundratalet, ska ett lag av autonoma humanoida robotar slå det mänskliga världscup-vinnarlaget under de officiella reglerna från FIFA.``
Att en robot är autonom betyder att roboten självständigt skapar en egen uppfattning om hur omvärlden ser ut med hjälp av sina sinnen och agerar utifrån denna uppfattning. En autonom robot kan kommunicera med andra robotar om det finns sinne och agerande som tillåter detta. Man vill inte skapa ett lag som sänder all information till en dator/server som räknar ut hur alla robotarna ska agera. Utan man vill istället få robotarna att kunna samarbeta med varandra utan att dom har all information om miljön runt om dem. Sinnena kan till exempel vara syn, hörsel och hur robotens maskineri fungerar. Att en robot är humanoid betyder att roboten ska vara människolik, både kroppsligt och i de agerande som roboten kan göra.
Det räcker inte med att man lyckas bygga de humanoida robotarna. För att kunna programmera roboten att spela smart, så måste det också göras framsteg på andra område,
T ex agentarkitektur, samarbete mellan agenter och inlärning. Eftersom teknologin att bygga humanoida robotar är under utveckling valde man att börja lite enklare. Man började därför med tre ligor.
Det är denna liga som jag har utvecklat mina spelare till. Denna ligan sker helt i den virtuella världen. Varje lag har 11 spelare. Spelarna är i detta fall program som kopplas upp mot ett program som heter Soccerserver och ger spelarna deras sinnesintryck och utför deras handlingar. Varje spelare har egna sinnen i form av: syn, hörsel och information om spelaren. Kommunikation mellan spelarna är tillåtet om den går igenom SoccerServern med hjälp av ett agerande vid namn say (säg). Det är meningen att simulatorn skall vara så nära verkligheten som möjligt och det är därför man lagt till offsideregeln. Man kan se SoccerServern som en simulator för hur de färdiga humanoida robotarna kommer att fungera på 2050-talet. Soccerservern används för att utveckla mjukvara som kommer att behövas för att styra robotarnas hårdvara. Simulatorligan är en bra miljö för att undersöka hur man ska göra för att få agenter att samarbeta med varandra, fastän de kan ha olika uppfattningar om hur miljön ser ut runt omkring dem. Anledningen till detta är den komplexa miljön som agenterna befinner sig i. Teorier om hur man ska lära upp agenten att agera rationellt testas också. Det finns programmerare över hela världen som sitter och programmerar agenter för simulatorligan.
Spelplanen är stor som ett pingisbord. Upp till fem robotar på varje sida, där robotens storlek är max 15![]() . Robotarna byggs av de deltagande lagen. Robotarna förflyttar sig på hjul och har en hastighet upp till två m/s. Bollen är en orange golfboll. Till skillnad mot simulatorligan så får man använda ett globalt seende av hela planen, vilket förmedlas till robotarna. Globalt seende betyder att robotarna får en översiktsbild över hela planen. Anledningen till att man tillåter globalt seende är att man vill ha forskning om hur man ska integrera information från sensorer som finns i miljön och sensorer som finns på robotarna, i autonoma realtidssystem. Detta är av intresse inom t ex intelligenta trafiksystem.
. Robotarna byggs av de deltagande lagen. Robotarna förflyttar sig på hjul och har en hastighet upp till två m/s. Bollen är en orange golfboll. Till skillnad mot simulatorligan så får man använda ett globalt seende av hela planen, vilket förmedlas till robotarna. Globalt seende betyder att robotarna får en översiktsbild över hela planen. Anledningen till att man tillåter globalt seende är att man vill ha forskning om hur man ska integrera information från sensorer som finns i miljön och sensorer som finns på robotarna, i autonoma realtidssystem. Detta är av intresse inom t ex intelligenta trafiksystem.

Här har man också fem spelare per lag. Planen är nu tre gånger tre pingisbord stor. Robotarna högsta diameter är 50 cm och matchen spelas med en Futsal-4 boll. Man tillåter i denna ligan bara sensorer på robotarna. Målen är färglagda och man har en vägg runt om planen så att robotarna kan lokalisera sig. Med hjälp av sensorerna på roboten tolkar roboten sin miljö och bestämmer därefter hur den ska agera för att dess mål ska uppfyllas. Dessa mål kan vara att skjuta bollen i mål, men kan också t. ex vara att täcka en spelare och flytta sig för att kunna göra en bra spark eller knuff på bollen.
Sony har startat en liga bestående av fyrbenta robotar. Man planerar att ha en helt autonom humanoidliga år 2002. Robotarna i denna ligan kommer att vara lika långa som människor. Man har sedan 1999 ändrat målet med RoboCup från:
´´ På mitten av 20-hundratalet, ska ett lag av autonoma humanoida robotar slå det mänskliga världscup-vinnarlaget under de officiella reglerna från FIFA.`` översättning från engelska[2].
Till:
´´ Till år 2050, utveckla ett lag av helt autonoma humanoida robotar som kan vinna mot det mänskliga världscup-vinnarlaget.`` översättning från engelska[3].
Tonvikten av mitt examensarbete handlar om hur man programmerar agenter att spela fotboll i RoboCups simulatorliga. Soccerserver heter det programmet som man kopplar upp agenterna till för att spela en match och för att de ska få sina sinnesintryck. Programmet är skrivet av Itsuki Noda och nya versioner av programmet utvecklas fortfarande. Jag utvecklade mina spelare till version 6.02 medan min manual var till version 5.00 [4]. Detta gjorde att vissa detaljer i manualen inte stämde överens med Soccerservern jag använde. När man tar ner Soccerserver från Internet så följer det med ett program vid namn Soccermonitor. Med hjälp av monitorn kan man visa spelarnas och bollen placering på planen och med hjälp av detta följa spelet. Man kan koppla flera monitorer till Soccerservern, vilket gör det möjligt att se matchen på flera ställen samtidigt. Varje spelare som ska vara med i matchen måste koppla upp sig mot servern. Kommunikation mellan server och klienten/spelaren sker med hjälp av UDP/IP sockets.
3.1 Soccerserverns modell av en fotbollsmatch
Soccerservern är uppbyggd på ett sådant sätt att det är enkelt att förändra spelarnas fysiska förmåga att spela fotboll. T ex förändra hur mycket spelaren ser och hör, hur snabbt spelaren kan springa eller hur ofta en spelare kan spurta och hur hårt man kan sparka på bollen. Jag kommer därför att ta upp en del av parametrarna som man kan ställa in och samtidigt förklara hur serverns hanterar en simulering av en fotbollsmatch. Alla parametrarna finns i bilaga A för de som vill ha mer information. I bilaga B finns konfigueringsfilen till de matcherna som spelades. Om man ändrar vissa parametrar till servern, kan man ta bort en del av problematiken med att spelaren inte har fullständig information om sin miljö. Jag valde att behålla den konfigurationsfil som följde med soccerserver och inte ändra i den, för att behålla svårigheterna i den miljö som soccerservern ger.
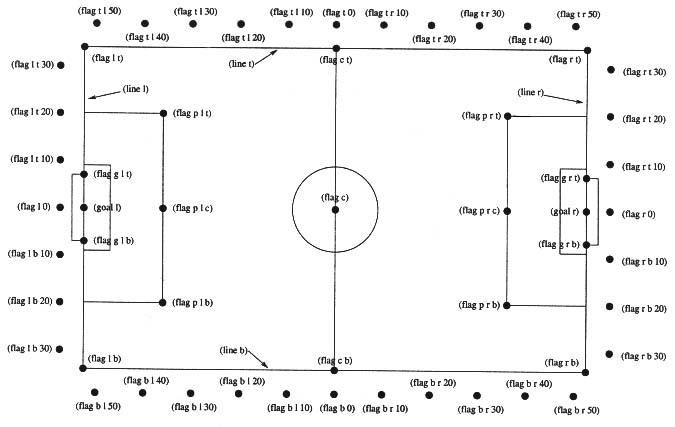
Planen för fotbollsmatchen är 105 meter lång och 68 meter bred. Alla objekt (flaggor, boll, spelare) på planen är tvådimensionella. I och runt om planen finns det markerade positioner som kallas flaggor. För att man ska kunna hantera matchen bättre, valde skaparna av soccerserver att dela upp fotbollsmatchen i rundor. Under varje runda så kan spelare göra tre agerande, men vissa agerande får inte göras under samma runda. Längden på en runda är i mitt fall 100 ms. Detta gör att spelaren kan göra ett agerande varje ca 33,3 ms. Längden på en halvlek är 3000 rundor vilket gör att en match tar lite mer än 10 minuter att spela (2*3000*0.1/60). Detta på grund av att det finns situationer då rundorna inte räknas upp varje 100ms. En av dessa situationer är vid mål. Två andra parametrar som kan ändras bestämmer hur ofta information om spelaren och visuell information kommer till spelaren. Information om spelaren är en form av känsel och kommer varje 100 ms. Visuell information får man varje 150 ms, vilket medför att man inte har färsk visuell information varje runda. Den visuella informationen skiftar också i kvalitet. Det vanliga seendet är inställt på 90 grader. Detta gör att spelaren med sin standardblick ser det som är mitt framför näsan och 45 grader åt höger och vänster. Hur bra spelarna hör på planen kan också ändras. Spelarna har också en energitillgång vilket minskar när de spurtar och ökar när de rör sig långsamt. Denna parametern kan också ändras.
3.2 Informationen från Soccerservern
Först i varje runda så får man en så kallad känselinformation från servern (sense_body). Här får spelaren reda på:
Alla riktningar ges i grader, där 0 betyder rakt framför, positiva vinklar är medurs, medan negativa vinklar är moturs.
Ex: (sense_body 0 (view_mode high normal) (stamina 3500 1) (speed 0 0) (head_angle 0) (kick 0) (dash 0) (turn 0) (say 0) (turn_neck 0))
Två rundor av tre så får spelaren visuell information. Informationen är uppdelad i:
All visuell information beror på om spelaren tittar åt objektets (flaggor, boll, spelare) håll. Om det inte finns en boll i spelarens synfält så kommer det inte att finnas någon information om bollen. Det är likadant med flaggor, med- och motspelare. Flaggorna som spelaren ser kan användas till att orientera spelaren. Informationen om med- och motspelare är av skiftande kvalitet beroende på hur väl spelaren ser med- eller motspelare. Detta gör att man ibland inte kan avgöra om det var en med eller motspelare som spelaren såg. Runt fotbollsplanen finns fyra linjer. Med hjälp av dessa linjerna kan spelaren få reda på i vilken riktning som spelaren ser. Linjerna anger en vinkel som är den minsta antalet grader (absolutbelopp) som spelaren måste svänga för att titta parallellt med linjen. I fallet ((l r) 46.1 -89)) så har vi att det är den högra linjen och -89 grader betyder 89 grader moturs. Eftersom spelaren är på planen så måste spelaren titta en grad moturs parallellt med sidorna mot det högra målet.
Ex: (see 25 ((g r) 46.1 0) ((f r t) 57.4 -35) ((f r b) 57.4 37) ((f p r t) 35.9 -33) ((f p r c) 29.4 0) ((f p r b) 35.9 35) ((f g r t) 46.5 -7) ((f g r b) 46.5 9) ((f t r 50) 58.6 -40) ((f b r 50) 58.6 42) ((f r t 30) 59.1 -29) ((f r t 20) 54.6 -20) ((f r t 10) 51.9 -10) ((f r 0) 50.9 0) ((f r b 10) 51.9 11) ((f r b 20) 54.6 22) ((f r b 30) 59.1 31) ((b) 5.5 9 1.43 -1.4) ((p) 1.1 82) ((p "mehi" 3) 5 2 -0.5 0.7 172 172) ((l r) 46.1 -89))
Spelaren får också information genom sin hörsel. Mina spelare använder sig inte av möjligheten att kommunicera med varandra. Detta gör att all information som mina spelare får antingen är från domaren eller från motspelare om motspelarna kommunicerar med varandra. Domaren säger till när det är t.ex. frispark, offside, mål eller kickoff.
Ex: (hear 0 referee kick_off_l)
3.3 Spelarens agerande till Soccerservern
Spelaren har 8 möjliga agerande/kommando med vilka han kan påverka miljö som han spelar fotboll i. Dessa är:
Med hjälp av move så kan spelaren placera sig på en specifik plats som spelaren anger. Detta agerande kan bara användas under speciella situationer t.ex. mål. Detta kommando får inte användas i samma runda som catch, dash, kick, turn eller turn_neck. Man kan då bara använda change_view och say i samma runda som man använt move.
Turn vänder spelarens kropp ett angivet antal grader där positiva gradtal medför medurs förändring och negativa gradtal medför moturs riktning. Kommandot får inte användas i samma runda som man använder catch, dash, move eller kick. Det kan användas med turn_neck, change_view och say. Om spelaren är i rörelse så minskar antalet grader som spelaren kan vända sig.
Dash används för att öka spelarens fart åt det hållet som spelaren står. Detta är den enda möjligheten förutom move som spelaren har att förflytta sig. Spelaren anger inte i vilken fart han vill röra sig åt ett visst håll, utan han får vända kroppen med turn och spurta flera rundor i rad med dash tills han fått den fart han vill ha. Spelarens fart minskar sedan varje runda som spelaren inte spurtar. Dash får inte användas i samma runda som man använder catch, kick, move eller turn. Man kan använda dash tillsammans med turn_neck, change_view och say.
Med kick så sparkar spelaren bollen. Bollen måste vara inom en viss radie från spelaren (1.085m i mitt fall) för att han ska kunna sparka på den. Desto närmare spelaren är bollen, desto hårdare kan spelaren sparka bollen. Förutom hur hårt spelaren sparkar på bollen så anger spelaren i vilken riktning som han vill att bollen ska flytta sig. Bollens hastighet och riktning bestäms av vektoraddition. När flera spelare sparkar på bollen så kommer vektorerna att adderas ihop för att få reda på den slutliga vektorn (storlek och riktning) som bollen har sparkats med. Om bollen redan är i rörelse kan bollen få en annan slutriktning än vad spelaren angivit med kick. Kommandot får inte användas i samma runda som man använder catch, dash, move eller turn. Det kan också användas med turn_neck, change_view och say.
Catch får bara användas av målvaken. Om bollen är inom en förbestämd rektangel framför målvaktens kropp, kan han använda detta kommando. När målvakten har fångat bollen med händerna får han använda move i rundan efter catch-kommandot, för att snabbt kunna ändra sin placering. Detta gör att målvakten kan göra en snabb och längre utspark. Detta kommando får inte användas i samma runda som dash, kick, move, turn eller turn_neck. Man kan alltså bara använda change_view och say i samma runda som man använt catch.
Med hjälp av say kan spelarna kommunicera med varandra. Vad spelaren har sagt får andra spelare reda på genom hörselsinnet från servern. Till skillnad från domarens meddelande som hörs överallt, så hörs say-meddelande bara en viss radie runt spelaren.
Change_view ändrar spelarens seende, från fokuserad till vid syn och kvaliteten på det han ser. Detta kan användas för att ta reda på om en ökänd spelare är medspelare eller motspelare. Genom att fokusera på en spelare långt borta så blir informationen om honom bättre. Men eftersom spelaren fokuserar så ser spelaren inte lika vidsynt.
Med turn_neck så vrider spelaren på sitt huvud. Detta kommando kan användas till att öka antalet objekt som spelaren får reda på i den visuella informationen.
4 Synkronisering och signalmodeller
Som jag skrev tidigare så kan spelaren göra tre agerande varje runda. Varje runda delas upp i tre tidsdelar, vilket i vårt fall är ca 33,3 ms långa. Spelaren kan inte skicka tre agerande under samma tidsdel utan spelaren måste sända ett agerande i varje tidsdel. Detta gör det blir viktigt att spelaren är synkroniserad med Soccerservern. Jag kommer hädanefter att använda begreppet agent för den egna spelaren. För att hantera signalhanteringen så valde jag i början att dela upp agenten i två delprogram: signalmottaging från servern och signalsändning till servern. Detta tänkte jag göra med processer eller trådar. Genom att använda processer eller trådar så kan flera delar av det man har programmerat köras samtidigt.
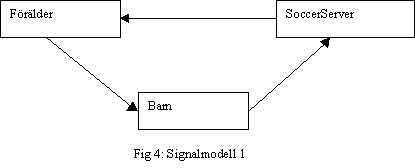
Min idé var att jag skulle ta emot information från soccerservern i föräldern som med hjälp av denna bestämde vad agenten skulle göra. Agentens handlingar skulle sändas till barnet över en socketport. Barnet skulle sedan sända över agentens handlingar till soccerservern vid rätt tidpunkt. Detta gör att barnet är den enda programdel som behöver bry sig om synkroniseringen mellan agenten och soccerserven. Denna signalmodell tyckte jag var bra för den gjorde att jag bara behövde synkronisera barnet med servern en gång. Mina agenter programmerade jag i C, så jag använde mig av Unix egna signaler för att hålla tider och underlätta kommunikationen mellan förälderprocessen och barnprocessen (SigInt, SigUsr1, SigAlrm).
Jag testade först att göra denna signalmodell med hjälp av processer, men det visade sig att min implementation fungerade dåligt. Programmet halkade efter. Sedan provade jag att programmera signalmodellen med hjälp av trådar. Även denna fungerade dåligt, detta handlade om att jag inte fick fram signaler till barnprocessen utan att avbryta föräldern med en SigInt (signal interrupt). Senare var jag på ett examensarbete om trådar och förstod då varför min lösning inte fungerade. För att signalerna ska komma fram till barnet så måste föräldern vara en signalhanterare som sänder signalerna vidare. Detta gör att en trådlösning kan göras med två barn (en mottagare och en sändare). Eftersom jag inte lyckats att få mina implementationer av denna signalmodell att fungera smärtfritt, så valde jag att välja en enklare signalmodell.

En implementation av den första signalmodellen med hjälp av trådar är att föredra. Med hjälp av denna så kan föräldern starta om programdelar om de stannar. För programmen stannar när UDP/IP sockets havererar. Men om man bortser från problem med sockets så kan den andra signallmodellen fungera bra.
Det som var bra med min första signalmodell var att agenten slapp synkronisera sig mer än en gång. Vad jag inte visste då var att det meddelande jag synkroniserade på inte sändes då serverns tid var 0 ms. Det var mycket bättre att synkronisera efter känselinformationen eftersom de sänds först varje runda. Detta kan visserligen ändras om man förändrar serverns parametrar, men hädanefter kommer jag att förutsätta att agenten får en känselinformation först i varje runda. Jag behövde också synkronisering från servern varje runda på grund av att jag hade bytt till den enklare signalmodellen. Jag valde att bestämma agentens agerande när han hade fått in nya synintryck. På grund av detta bestämmer jag vanligtvis vad jag ska göra de nästa två rundorna när visuell information har tagits emot. Detta gör att agenten kan använda alla tidsdelar. De saker som agenten bestämmer sig för att göra sparas i en lista. För att se till att agenten inte agerar på gammal information från servern (om programmet inte hinner med), skickar jag inte agentens beslut till servern förrän jag vet att det inte finns mer information från servern.
Exempel:
|
Tid |
Agerande |
Tidsdel |
Vänta till |
Händelse |
|
100ms |
1 |
Agenten får känselinformation och ställer om sin klocka. |
||
|
110ms |
1 |
1 |
133ms |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
|
140ms |
2 |
2 |
166ms |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
|
160ms |
Agenten får syninformation och går in i beslutsfattande läge. (servern skickade syninformationen vid 150ms). |
|||
|
180ms |
3 |
3 |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
|
|
200ms |
1 |
Agenten får känselinformation och ställer om sin klocka. |
||
|
210ms |
4 |
1 |
233ms |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
|
240ms |
5 |
2 |
266ms |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
|
270ms |
6 |
3 |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
|
|
300ms |
1 |
Agenten får känselinformation och ställer om sin klocka. |
||
|
310ms |
Agenten får syninformation och går in i beslutsfattande läge. (servern skickade syninformation vid 300ms) |
|||
|
320ms |
7 |
1 |
333ms |
Agenten får ingen ny information och väljer att skicka det agerande som är först i listan. |
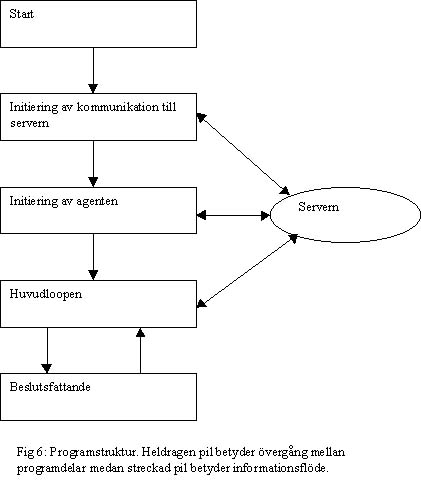
Strukturen ovan är den jag använt när jag har programmerat mina agenter att spela fotboll. Programmet startar med att initiera kommunikationen med servern som sker med UDP/IP sockets. När detta har gjorts, sänder agenten vilket namn laget har som han vill spela i. Agenten får då reda på vilket nummer han har. Detta nummer är från 1 till 11 där jag väljer att 1:an ska vara målvakt, 2-4 ska vara anfallare, 5-7 ska vara mittfältare och 8-11 är backar.
Huvudloopen väntar på information från servern. Om den får känselinformation så läggs informationen in och agenten synkroniseras mot servern. Om agenten får see från servern så går programmet in i ett beslutsfattande läge. Denna struktruering av programmet gör att man enkelt kan ändra agentens sätt att agera genom att bara ändra den beslutfattande delen. Huvudloppen skickar de besluten som har fattats i rätt ordning och tid till servern om programmet hinner med. Jag lade också till möjligheten att skapa kommando som man skriver in via tangentbordet. De två kommandona som jag lade in är avsluta och visa med- och motspelarna. Det senare kommandot ger en utskrift på vilka med- och motspelare som agenten känner till.
Beteenden används i många lag som utvecklats till RoboCup. Jag valde att agenten skulle ha beteende som bestämde hur agenten skulle agera. På grund av att agenten inte kan göra visa agerande samtidigt valde jag att använda ett beteende i taget. Men det är möjligt att göra beteenden som kan köras samtidigt, t.ex. kan man ha ett beteende för att få mer syninformation som ändrar agentens seende samtidigt som agenten vänder sig. Med hjälp av agentens situation bestämmer beteendet agerandet, från att inte agera alls till att bestämma vad som ska göras de nästa tio rundorna. Dessa agerande läggs i en lista som agenten sedan utför. För att kunna ha beteende som pågick i flera rundor gjorde jag vissa beteende tvingande, vilket gör att man inte kan lägga till nya agerande förrän det gamla beteendet är färdigt. Eftersom det tar flera år att skapa ett bra lag till Robocup bestämde jag mig för att begränsa mig till att göra enkla beteende till mina agenter. Detta gör att mina agenter inte spelar på elitnivå.
Informationen från servern om bollen och spelare som agenten får genom sin syn är skiftande i kvalitet. Detta beror på hur väl agenten ser bollen eller spelaren. De enda informationerna som agenten är säker på att få om agenten ser objektet är riktning och avstånd till objektet. Jag valde därför att bara använda mig av avståndet och riktningen till spelare och bollen. Detta gör att jag då inte kan göra en uppskattning om var spelaren eller bollen kommer att vara nästa runda på grund av att jag inte använder mig av avståndsförändring och riktningsförändring som ibland finns med som extrainformation om spelaren eller bollen. Detta kan ses som att spelarna och bollen runt agenten är stillastående.
Som jag skrev tidigare så kan agentet hålla reda på sin position med hjälp av flagorna. En möjlighet som används flitigt bland lagen i simulatorligan är att räkna ut exakt position med hjälp av agentens synriktning (som man kan få fram med hjälp av linje informationen) och flaggorna. Flaggornas placering är ju kända och eftersom man har riktningen till flaggan och avståndet så kan agenten räkna ut sin position i x- och y-led. Detta använde jag mig av när jag skapade målvakter, men inte när jag skapade utespelare. Jag valde istället att använda mig av agentes synrinktning och en del flaggor. Detta betyder att utespelarna oftast inte vet var de är på planen, men de vet vanligvis åt vilket håll motståndarnas mål är.
Syninformationen om vem spelaren är som agenten har sett kan skifta i kvalitet, här är de tre möjliga fallen:
1 Agenten ser både spelarens lag och nummer.
2 Agenten ser bara spelarens lag.
3 Agenten ser varken spelarens lag eller nummer.
I första fallet så vet vi exakt vilken spelare det är, men i andra och tredje fallet så vet agenten inte detta. Eftersom jag inte hittade någon fakta om hur andra programmerare löser detta problemet så gjorde jag egna lösningar.
Min första lösning gick ut på att bara spara de spelare som agenten visste identiteten på. Detta gör att agenten bara bryr sig om de spelare som han ser bra. Agenten kan med denna metod hålla reda på spelare som han har sett för ett tag sedan, men agenten tar inte med de spelare som han inte vet identiteten på. Detta gör att denna lösning fungerar mindre bra. Min andra lösning brydde sig därför inte om exakt identitet utan brydde bara sig om vilket lag spelaren spelade i. Denna ide gick ut på att agenten bara skulle bry sig om det han hade sett denna sista rundan. Agenten fick nu med spelare från fall 1och 2, men kom inte ihåg vad han hade sett innan. Detta medför att han bara vet om de spelare som är 45 grader åt höger och vänster från agenten näsa.
I min tredje lösing så ville jag ha med alla tre fallen. Agenten fick nu försöka komma på vilken spelare som det troligtvis var han såg. Jag valde att ge den nya informationen till den spelare som var närmst med sin gamla information. Hur långt det är mellan gammal och ny information kan räknas ut med hjälp av cosinussatsen. L3=L1*L2*cos a. Där a är vinkelskillnaden mellan ny och gammal vinkel.
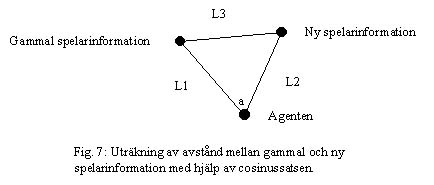
Om man vet spelarens lag så kommer den spelare som har minst L3 i det laget att få sin information uppdaterad. Om man inte vet spelarens lag så kommer den spelare som har minst L3 att få sin information uppdaterad. Jag tar inte hänsyn till agentens egen förflyttning eller hur gammal informationen om spelaren är. Att uppdatera var spelarena runt agenten är på detta sättet kommer att innebära att man får in fel information ibland. För att agenten inte ska tro att det finns en spelare på ett ställe där det inte finns någon, valde jag att bara använda information som var 10 rundor gammal eller mindre.
7 Beslutsfattningen och beteendena
Beslutsfattningen bestämmer vilket beteende som ska användas och beteendet bestämmer vilket agerande som sänds till Soccerservern. Dessa beteende är byggstenarna som jag använder för att bygga upp agentens agerande. Eftersom målvakten i ett lag har möjligheten att ta bollen med händerna och det är målvaktens huvuduppgift är att skydda målet så valde jag att göra två versioner av mitt beslutsfattande. En för målvakten och en för utespelare. Jag går först igenom belutsfattningen för målvakten och utespelarena för att i 7.3 beskriva beteendena. Alla längder som styr beslutsfattningen är inställda konstanter som kan ändras, vilket gör det enkelt att ändra beslutsfattningen.
Målvaktens huvuduppgift är att förhindra att motspelarna gör mål. För att målvakten ska veta var han står, använde jag mig här av exakt positionering vilket kan räknas fram med hjälp av flaggorna. Jag gav målvakten en startplacering som ligger två meter framför målet i sidled och i mitten i höjdled.
Målvaktens beteende:
Målvakten är beroende av att veta var bollen är och undersöker därför varje gång han gör beslut om han vet var bollen är. Om målvakten inte känner till var bollen är så startar "hitta bollen"-beteendet. Om målvakten känner till bollens placering så beror vilket beteende han använder på placeringen av bollen. Först undersöker han om han kan fånga bollen med händerna. Detta kan han försöka göra om bollen är inom en rektangel framför målvakten som är 2 m lång och 1 m bredd.
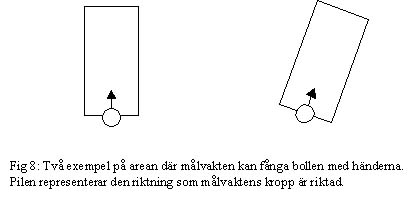
Om bollen är inom rektangeln så använder målvakten "fånga bollen med händerna"-beteendet. Om målvakten lyckas ta bollen så kommer han att använda sig av "snabb utspark med snabb hemförflyttning"-beteendet vilket sträcker sig över 12 till 13 rundor framåt i tiden. Om bollen låg utanför rektangeln så undersöker målvakten om han kan sparka på bollen. Detta kan han göra om avståndet till bollen är mindre eller lika med 1.085m. Om målvakten är inom denna radie från bollen så kommer han att använda sig av "sparka bollen"-beteendet.
Om bollen är inom 15 meter och målvakten inte har sprungit för lång från mål så kommer han att använda "spring direkt till bollen"-beteendet. Som det är nu så har målvakten kommit för långt från mål då han är 12 meter i x-led från målet. Om bollen är emellan 15 och 30 meter från målvakten och målvakten är nära målet, så försöker målvakten att täcka målet med "täck mål"-beteendet. I de fallen då målvakten inte har bestämt sig för något av det tidigare beteendena så använder han "gå till startplacering"-beteendet.
Utespelarens uppgift är att ta bollen från motspelare för att sedan göra mål, genom att sparka bollen mot och slutligen i motståndarnas mål. Det är samma beslutsfattning som bestämmer vilket beteende som ska användas för alla utespelarna. Det finns viss skillnad i de olika utespelarna agerar men denna skillnad ligger på beteendenivå. Mer om detta i kapitel 7.3.
Utespelarens beteende:
Utespelaren är också beroende av att veta var bollen är och letar upp bollens placering med hjälp av "hitta bollen"-beteendet om han inte känner till den. Om bollen finns inom 1.085m från utespelaren så kommer han att sparka till bollen med "sparka bollen"-beteendet. I de tillfällena då bollen är för långt borta så undersöker utespelaren om han är närmast bollen bland sina medspelare med hjälp av cosinussatsen.
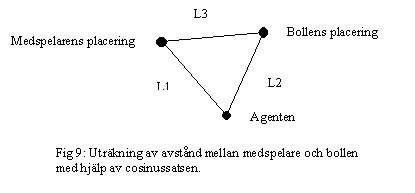
Om utespelarens avstånd till bollen (L2) är mindre än alla medspelares avstånd till bollen (L3) (som utespelaren vet om), anser utespelaren att han är närmst bollen. Då använder utespelaren "spring direkt till bollen"-beteendet. Om utespelaren inte har använt några av de tidigare beteendena så använder utespelaren "rörelse i längdled"-beteendet.
Hitta bollen. Detta beteende försöker hitta bollen genom att agenten ändrar kroppens riktning. Om agenten inte har någon aning om var bollen är så ändras kroppens riktning 90 grader medurs. I vissa fall är det mer troligt att bollen är i en viss vinkel på grund av gammal information. I dessa fallen ändras kroppens riktning 90 grader åt det hållet agenten tror att bollen är. Orsaken till att man alltid vänder sig 90 grader är att agenten synfält är 90 grader, vilket medför att agenten på fyra synintryck kan leta efter bollen i alla riktningar. Om bollen är stillastående så kommer agenten att hitta den på fyra synintryck, men om bollen rör sig så kan det ske att det tar längre tid att hitta bollen.
Sparka bollen. Min idé här är att agenten ska sparka bollen parallellt med sidorna i riktning mot motståndarnas mål om agenten inte ser några målflaggor. I de fall då agenten ser målflaggor försöker han göra mål. Med hjälp av synintrycken från linjerna så kan agenten ta reda på i vilken riktning han ser. Om agenten inte har vridit sitt huvud så har hans kropp samma riktning som synriktningen. Med hjälp av detta så kan agenten räkna ut hur många grader han behöver ändra kroppens riktning för att titta i den riktningen som är parallell med sidorna mot motståndarnas mål.
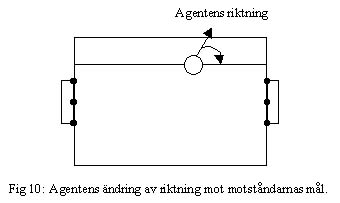
Det finns tre flaggor vid motståndarmålet som används för att göra mål. Om flaggan i mitten syns, ska agenten sparka i riktningen mot flaggan. Annars använder agenten sig av stolpflaggorna för att bestämma hur han ska sparka. Om agenten ser båda flaggorna så sparkar han mellan dem, men om agenten bara ser en av stolpflaggorna så sparkar han fem grader innanför stolpflaggan in i målet.
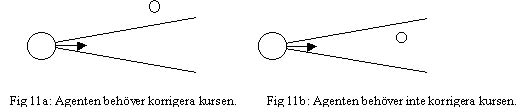
Spring direkt till bollen. Detta beteende undersöker först om det finns spelare mellan agenten och bollen. Om det finns spelare mellan agenten och bollen så springer agenten runt spelaren som står i vägen. I de fallen då det inte finns några spelare mellan agenten och bollen, kontrollerar agenten hur stor skillnad det är mellan bollens riktning och agentkroppens riktning. Om skillnaden är mindre än 10 grader åt både höger och vänster så springer agenten direkt, annars gör agenten en kurskorrigering innan han springer.
Rörelse i x-led. Med hjälp av detta beteende så förflyttar utespelarna sig förutom i de fallen då de använder "spring direkt till bollen"-beteendet för att förflytta sig. Hur detta beteende fungerar beror på om agenten är en back, mittfälltare eller anfallare. Först undersöker agenten vilka spelare som finns runt bollen för att veta om det finns något lag som kontrollerar bollen. Om det finns både med- och motspelare nära bollen så anser agenten att det är hans lag som kontrollerar bollen. Alla förflyttningar i detta beteende är i en riktning som är parallell med sidorna mot antingen det ena eller det andra målet.
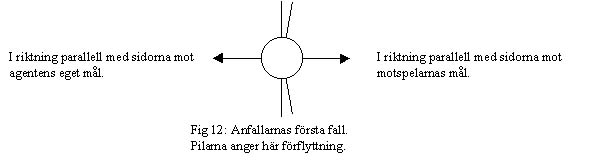
I det andra fallet då motspelarna har bollen så kommer anfallarna att röra sig med 10% av vad agenten max kan prestera. Till skillnad från det förra fallet så finns det inte i detta fallet några vinklar som medför att anfallaren inte rör sig.
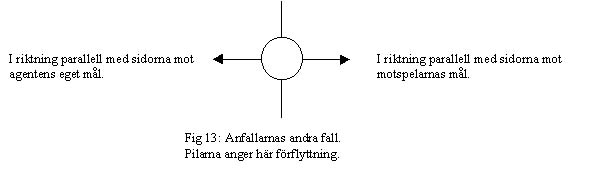
Orsaken till att jag har programmerat anfallarna så här är att jag ville att de skulle snabbt röra sig hemåt om medspelarna har bollen för att de inte ska ta emot bollen i en offside situation. Anfallarnas uppgift är att flytta bollen mot motståndarnas mål och göra mål. Att ta bollen från motspelare på egen planhalva är en uppgift som oftare görs av backarna.
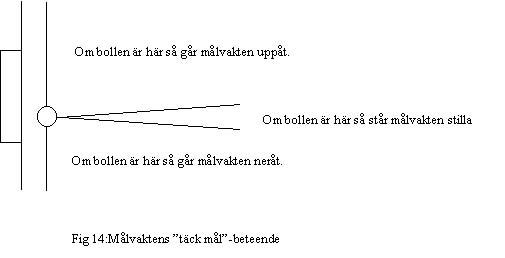
Täck mål. Detta beteende använder bara målvakten. Detta beteende kan bara väljas om målvakten står nära målet (i x-led) och vet var bollen är som också ska vara mellan 15 och 30 meter från målvakten. Beteendet går ut på att målvakten rör sig uppåt, nedåt eller står stilla för att täcka målet från bollen. Jag valde att målvakten skulle flytta sig om bollen var mer än fyra grader skild från vektorn som har riktningen parallell med sidorna mot motspelarnas mål. Målvakten rör sig på en linje framför målet. Men för att målvakten inte skulle gå för långt uppåt eller nedåt valde jag att han bara kunde röra sig inom en viss radie. Min idé var att agenten inte skull göra några nya förflyttningar som skulle öka radien om den var högre än 4.5 meter. Förflyttningar som minskade radien tilläts även om radien var större än 4.5 meter. Anledningen till att målvakten kan komma längre än 4.5 meter från startpositionen är att när målvakten rör sig så anger man hur målvakten ska spurta.
8 Reinforcement learning och neurala nätverk
Agenter som lär sig av den erfarenhet de får när de utför sin uppgift borde fungera bättre än agenter som en gång lärt sig hur de ska agera och inte ändrar detta agerande. Detta på grund av att den som programmerar agenten vanligtvis inte kan se alla möjliga situationer som agenten kan råka ut för. Men hur bra självlärande agent blir beror också på hur man programmerar självinlärningen. För att testa om självinlärning (reinforcement learning) kunde göra mina fotbollspelande agenter bättre så valde jag att göra ett självlärande "sparka boll"-beteende. Jag valde att implementera detta beteende genom att använda mig av ett neuralt nätverk. För att slutligen testa detta självlärande "sparka boll"-beteende så lätt jag göra ännu ett lag som då hade det nya beteendet istället för enkla "sparka boll"-beteende. Efter att jag hade gjort detta lag färdigt så spelade jag matcher mellan lagen för att testa vilket beteende som fungerade bäst. Men innan vi går in mer på detta så kanske jag skulle ta upp mer om hur neurala nätverk fungerar.
Neurala nätverk kan ses som en modell över hur en hjärna fungerar. Nätverket kan byggas upp av perceptroner. Om summan av insignalerna med sina vikter till en perceptron är mer än ett visst värde (tröskeln) så kommer man att få utsignalen 1 från perceptronen annars ger perceptronen ut 0. Detta gör att man kan bygga upp ett (binärt) neuralt nätverk som ger önskade utsignaler beroende på insignalerna.
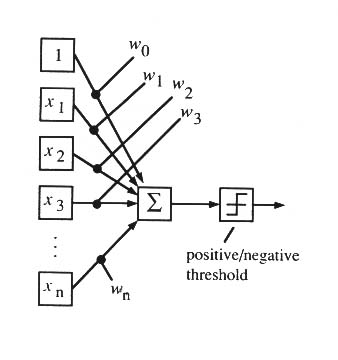
Med hjälp av ett flerlagers nätverk, kan man lägga in vilken funktion som helst för att bestämma utsignalerna beroende på insignalerna. Problemet är att det är omöjligt [6] att programmera detta för hand. I flerlagers nätverk tar man bort antagandet att insignalerna och utsignalerna måste vara binära.
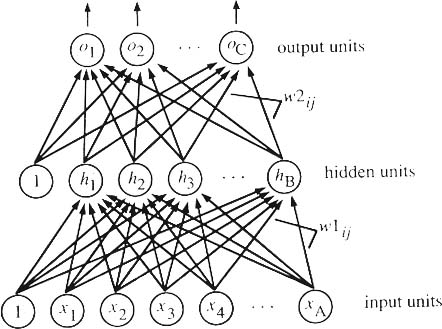
Det flerlagers neurala nätverket måste läras upp för att kunna bestämma utsignalerna rätt beroende på insignalerna. Iden är att man startar med vikterna randomiserade och sedan ändrar dessa till man får önskande utsignaler. När man lagt in sina insignaler till nätverket räknar nätverket fram utsignalerna. Detta gör nätverket genom att varje enhet i det första lagret räknar ut vilken utsignal den ska ge. Dessa utsignaler används sedan som insignaler till det andra lagret. Det andra lagret räknar nu ut utsignalerna för hela nätverket. Att låta nätverket räkna ut sina utsignaler beroende på sina insignaler kallas propagering. För att ha möjligheten att ändra vikterna, använder man sigmoidfunktionen som aktiveringsfunktion vilket gör det möjligt att propagera baklänges. Först propagerar nätverket framlänges, räkna ut hur mycket fel nätverket har, och ändrar vikterna med bakåtpropagering så att svaret närmar sig det man vill ha.

För att agenten ska kunna göra beslut så måste han veta vilken status/tillstånd som han är i. Dessa tillstånd kan bestämmas antingen genom indata från perceptorerna (agentens sinne) eller vara interna som agenten själv har skapat [2]. Detta beror på omgivningen runt om agenten. Agenten kan antingen vara en passiv elev eller aktiv elev. En passiv elev tittar på sin omgivning och försöker lära sig utifrån de olika tillstånden, medan en aktiv elev också måste agera med den lärda informationen. Agenten får feedback (återkoppling) som beror på agentens agerande och/eller tillstånd. Denna typen av återkoppling kallas reinforcement (förstärkning) eller belöning. Dessa belöningar kan fås genom agentens sinne eller så kan de bero på agentens tillstånd. I vissa fall så kan man ha inlärning som ger direkt belöning eller bara ger belöning vid ett sluttillstånd.
Exempel: en agent som ska spela schack.
Agentens sinne är var pjäserna står på schackbordet och vilken spelare han är (agenten får sina indata när det är hans tur). Dessa sinnena bestämmer också vilket tillstånd som agenten befinner sig i, vilket gör att agenten inte behöver ha några interna tillstånd. Schackagenten kan här ses som en aktiv elev som lär sig genom att spela många matcher, men kan också vara passiv (titta på när två andra spelare spelar en match). Man kan nu tänka sig flera former av belöningar som kan lära agenten. Första exemplet på belöning är att agenten får reda på om han har vunnit i slutet av matchen. En annan typ av belöning kunde vara att ha en belöningsfunktion som räknar ut hur bra agentens placering är efter varje drag. Detta beror helt på hur programmeraren väljer att skapa sin agent.
I mitt fall (sparkbeteendet), så används inlärningen i bara ett beteende, vilket medför att det inte finns något efterföljande tillstånd efter att agenten har använt beteendet, som kunde ge någon form av belöning. Belöning får agenten genom en belöningsalgoritm som undersöker om agentens spark var bra eller dålig. Agentens tillstånd (när han ska sparka på bollen) får man med hjälp av agentens sinne. I detta fallet så är agenten en aktiv elev eftersom han måste testa sparkar för att lära sig hur han ska sparka.
8.3 Modellen av världen runt agenten
För att mitt beteende skulle kunna avgöra i vilket tillstånd han var så skapade jag en modell av omgivningen runt agenten. Denna modell bestämmer vilka insignaler som jag sedan använder i mitt neurala nätverk. Jag delade upp agentens synfält i zoner där med eller motspelare och vissa intressanta flaggor kunde finnas. Eftersom mina "sparka boll"-beteende förutsätter att bollen är inom en viss radie från agenten så behövde bollen inte representeras i denna värld. Den svarta cirkeln representerar agenten och pilen representerar agenten synriktning (vilket förväntas vara samma som kroppsriktningen). Det finns 14 olika zoner runt om agenten. De streckade objekten anger hur långt det är från agenten till hel och halvcirklarna.
Insignaler jag nu bestämde mig för var:
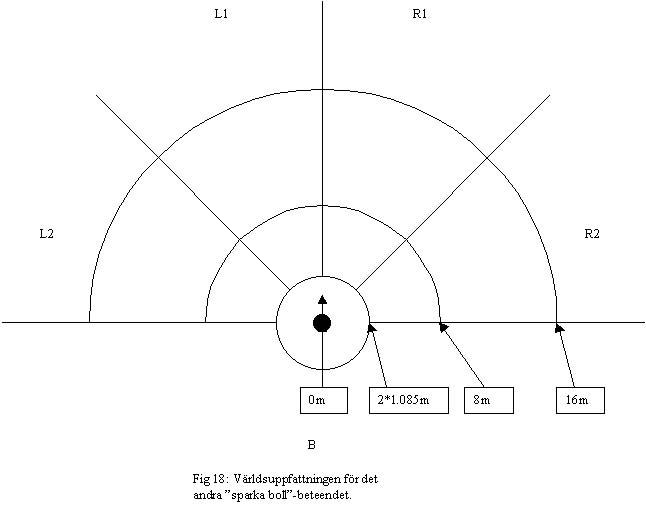
Jag valde att ha 14 utsignaler som är möjliga riktningar och vilken styrka som agenten ska sparka till bollen. Utsignalerna var:
När jag nu hade gjort ett neuralt nätverk som med hjälp av insignalerna kunde propagera fram utsignaler, så var det dags att skapa självinlärningen. Varje gång någon av de agenter som har det nya sparkbeteendet ska använda beteendet så tar agenten fram insignalerna till det neurala nätverket, propagerar utsignalerna och väljer att sparka efter den utsignal som har störst värde. När sparken har utförts så startar en belöningsalgoritm som försöker komma på om sparken var bra eller dålig. Frågan är nu hur man ska ändra nätverket om det var en bra eller dålig spark. Min idé gick ut på att om det var en bra spark så ökar man värdet för denna spark och om den var dålig så minskar man värdet för denna spark. Detta gör att man bakpropagerar bara för den spark som man använt. Agenten ändrar bara vikter som har med den valda sparken att göra. Ett annat sätt skulle vara att göra sannolikheten för andra sparkar mindre samtidigt som man ökade den använda sparken, så att de andra sparkarna skulle gå mot utsignalen 0. Med min ide så kan man istället ha flera sparkar som ligger nära varandra. För det är möjligt att det finns flera bra sätt att reagera på insignalerna. Nackdelen med min ide är att det nog tar längre tid för bra sparkbeteende att utmärka sig.
Varje runda efter som agenten har sparkat på bollen, försöker han avgöra om sparken var bra eller dålig. Detta pågår ända tills belöningsalgoritmen har givit ett svar. Belöningsalgoritmen ger svar i dessa situationerna:
Agenten får ingen belöning för att han själv springer ifatt bollen efter att han sparkat på den. Detta var för att agenten inte skulle få ett nätverk som bara sparkar lite framför sig själv och därför får hög belöning. Vad jag ville få fram var ett beteende som passar medspelare och gör mål.
När jag nu hade skapat ett självlärande beteende så testade jag detta först med 1 spelare i varje lag. Vad jag fick se var en spelare som sprang ifatt bollen och sparkade den snett 22 grader till höger, för att sedan igen upprepa detta. Det kan liknas vid att han rörde sig i en snurrande spiral nedåt för att slutligen sparka bollen utanför plan. Efter tester med fler spelare så valde jag att ge nätverket vissa förkunskaper:
De fem första förkunskaperna gör att agenten sparkar bollen mot motståndarnas mål om agenten inte ser några med- eller motspelare. Resten av förkunskaperna är till för att agenten ska göra mål då han ser motståndarmålets flaggor. Efter att jag hade lagt till förkunskaperna, kunde det nya laget göra mål. Jag lade inte till några förkunskaper om hur agenten skulle hantera motspelare och hur agenten skulle passa. Detta ville jag att agenten skulle lära sig själva.
För att testa mina "sparka boll"-beteenden så bestämde jag mig för att lära upp mitt självlärande "sparka boll"-beteende genom att spela 40 matcher för att se om det blev bättre.
Efter 20 matcher blev ställningen:
Vissa spelare hade lärt sig att passa i enstaka situationer med det självlärande beteendet, men de hade problem att hålla reda på vem som var med- och motspelare, vilket medför att bollen ibland passas till motspelare. Särskilt backarna hade lärt sig att passa spelare framför det egna målet vilket medförde att det blev självmål när medspelarna missade att ta bollen. På match 10 så gjorde de 11 spelarna 119 sparkar där 49 var bra och 70 var dåliga. Denna matchen förlorade det självlärande laget med 1-4.
På grund av det dåliga resultatet för det självlärande beteendet efter 20 matcher så valde jag att ändra detta beteende något. Den första förändringen var att lägga till 4 nya insignaler till det neurala nätverket som skulle förhindra självmålen. Dessa 4 insignalerna höll reda på om mittpunkten av sitt eget mål fanns i L1, L2, R1 eller R2.
6 nya förkunskaper lades därefter till:
De fyra första nya förkunskaperna gjorde att agenterna undvek att göra passningar när de såg mittmållflaggan för det egna målet. Detta för att undvika självmål. Jag ville med de 2 sista förkunskaperna öka passningen inom laget.
Förkunskapen:
Linjen som är parallell med sidorna mot motståndarnas är i B och alla andra insignaler är noll så ska agenten sparka bollen 100 % i B.
Ändrades till:
Linjen som är parallell med sidorna mot motståndarnas är i B och alla andra insignaler är noll så ska agenten sparka bollen 20 % i B.
Så att man skulle minska det antalet bollar som gick till motspelarna genom att man sparkade bollen 100 % bakåt.
Jag spelade nu 40 matcher och resultatet blev:
Detta visar att under de förutsättningarna jag hade på planen så fungerar ett enkelt beteende bättre än det självlärande. Anledningen till att det självlärande beteendet inte fungerar bättre, är att agentens uppfattning om vilka spelare som är runt honom ofta blir felaktig. Rörelsebeteendet som agenterna använder gör också att passningar kan vara svåra att göra på grund av att spelarna klumpar ihop sig. Här är några förslag på förbättringar som skulle få det självlärande beteendet att fungera bättre:
När jag utvecklade mina agenter så delade jag upp detta i två programdelar:
Uppdelningen gör att man kan skapa många olika sorters agenter med olika typer av beslutsfattning utan att behöva göra om grundprogrammet. Denna ide är inte bara användbar för utveckling av agenter till RoboCup utan kan användas till varje typ av agentskapande där man kan göra en klar uppdelning.
Även om jag i början ville använda mig av processer eller trådar istället för min enkla modell, blev jag nöjd med grundprogrammet. Under de fyra sista matcherna som spelades så skrev jag ner statistiken på hur ofta programmet inte var tillräckligt snabbt för att hinna sända sina kommandon. Det högsta värdet jag fick fram var 174 missade tidsdelar under en match då kommando kunde ha skickats. En match har 18000 tidsdelar och det ger att agenterna missade mindre än 1 % av tidsdelarna. Jag använder vanligtvis bara en tidsdel per runda, vilket gör att antalet riktiga kommando som jag ville sända som gick förlorade kan då vara ännu lägre.
Vad jag är mindre nöjd med i grundprogrammet:
Jag programmerade en beslutsfattning för målvakter och en för utespelare som byggdes upp av beteende. Utespelarnas beslutsfattning är jag nöjd med. Målvaktens beslutsfattning fungerade också bra, men kunde ha en jämnare övergång mellan "spring direkt till bollen" och "gå till startplacering"-beteendet, som tar bort situationer där målvakten springer till bollen och sedan ifrån bollen på grund av att målvakten kommit för långt från mål.
Även om mitt enkla sparkbeteende blev bättre än mitt självlärande sparkbeteende så tror jag ändå att ett självlärande beteende är bättre under rätt omständigheter. Ett passande lag fungerar bättre än ett lag där spelarna bara sparkar iväg bollen mot motståndarnas lag. Spelhanteringen medförde att agenterna sparkade bollen till motspelarna på grund av att agenterna tog fel på med- och motspelare. Spelarnas positionering på planen gjorde att passningar med det självlärande beteendet blev mindre bra, för att spelarna samlade sig i klungor.
Förbättringar som kan göras till beteendena:
Den som är intresserad av att veta mer om simulatorligan eller RoboCup i allmänhet kan läsa mer på: http//www.robocup.org/. För den som tänker utveckla agenter till RoboCup så vill jag hänvisa till simulatorligans maillista [7] som kan vara bra om man är osäker om något. Jag vill också nämna två artiklar som jag tyckte var intressanta:
Chritoph G Jung. Layered and Resource Adapting Agents in the RoboCup Simulation [8].
Paul Scerri. A Multi-Layered Behaviour Based System for Controlling RoboCup Agents [9].
[1] Minoru Asada. RoboCup Today and Tomorrow - What we have learned. Artificial Intelligence volume 110 number 2 June 1999 ISSN 0004-3702
[2] Stuart Russel, PeterNorvig. Artificial Intelligence A modern Approach. ISBN 0-13-360124-2
[3] http://www.robocup.org/
[4] Emiel Corten, Klaus Dorer, Fredrik Heintz, Kostas Kostiadis, Johan Kummeneje, Helmut Myritz, Itsuki Noda, Jukka Riekki, Patrick Riley, Peter Stone, Tralvex Yeap. Soccerserver Manual Ver.5 Rev. 00 beta May 14 1999
[5] http://ci.etl.go.jp/~noda/soccer/server/
[6] Elaine Rich, Kevin Knight. Artificial Intelligence ISBN 0-07-100894-2
[7] robocup-sim-l@usc.edu
[8] Chritoph G Jung. Layered and Resource - Adapting Agents in the RoboCup Simulation.
RoboCup-98: Robot Soccer World Cup II, Springer 1999, LNCS vol. 1604. M Asada, H Kituna (editorer)
[9] Paul Scerri. A Multi-Layered Behavior Based System for Controlling RoboCup Agents.
RoboCup-97: Robot Soccer World Cup I, Springer 1998, LNCS vol. 1395. H Kituna (editor)
Utdrag ur [4].
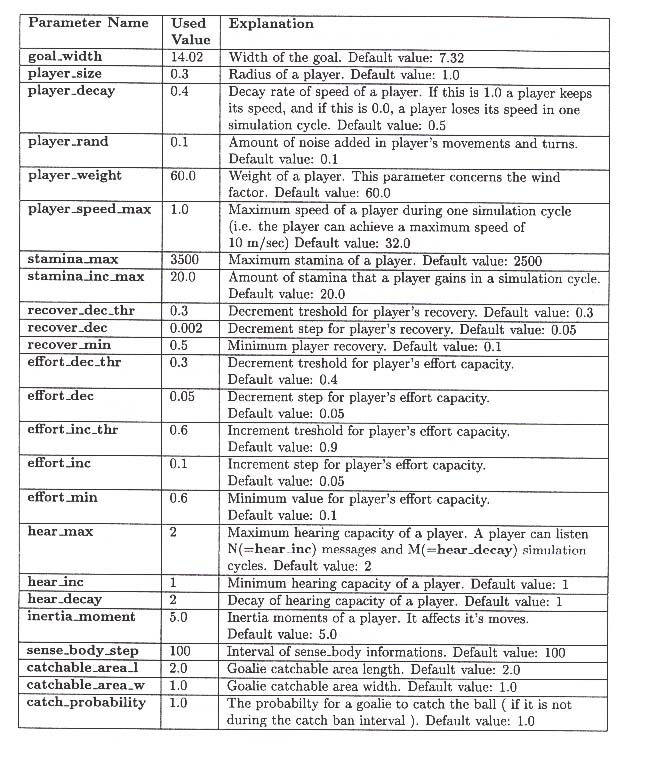
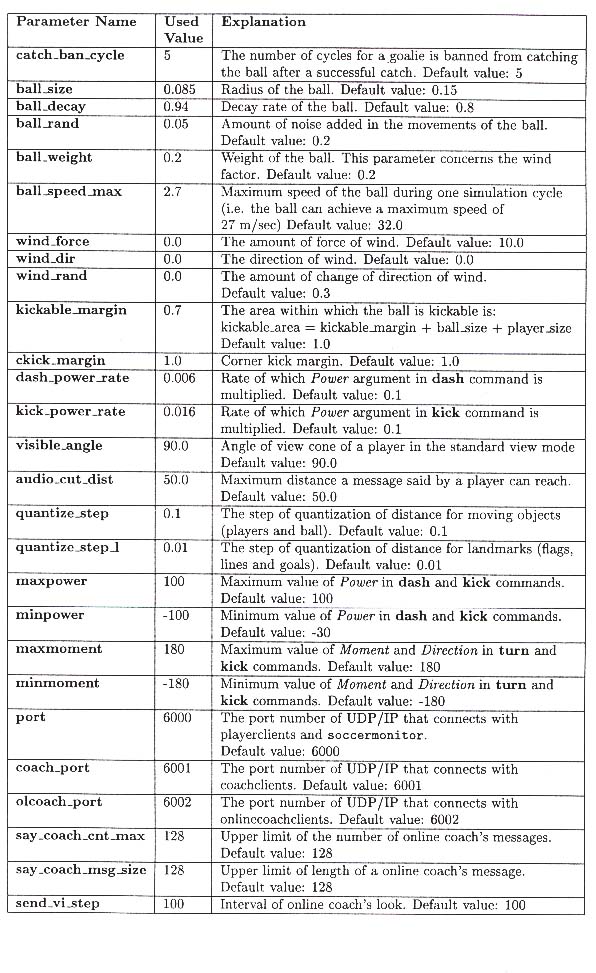
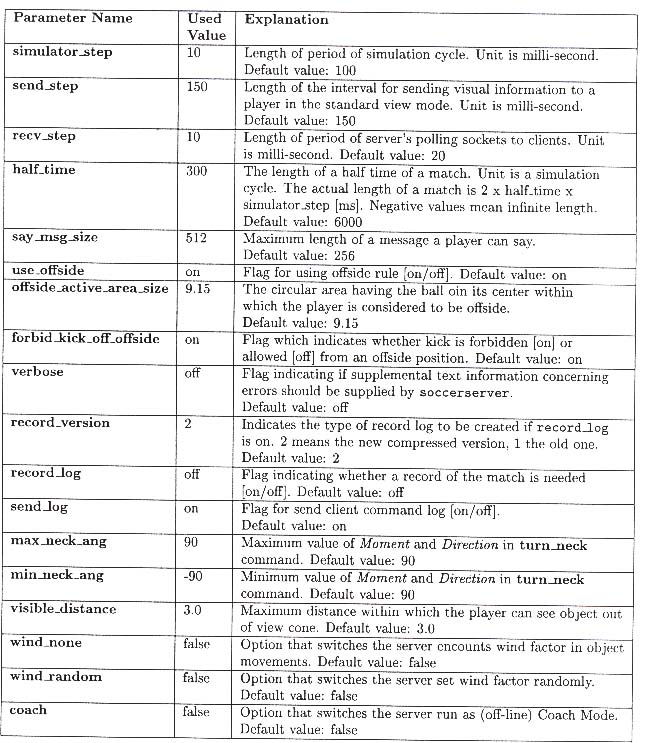
Detta är en utskrift av konfigueringsfilen till SoccerServern som jag använde under min utveckling och testning av agenterna.
# Configurations for soccerserver
# Lines that start '#' are comment lines.
# width of goals (default 7.32)
goal_width : 14.02
# size, decay, random parameter, weight, maximum speed of players
# (default 1.0, 0.5, 0.1, 60.0, 32.0)
player_size : 0.3
player_decay : 0.4
player_rand : 0.1
player_weight : 60.0
player_speed_max: 1.0
# maximum and recovery step of player's stamina (default 2500.0, 50.0)
stamina_max : 3500.0
stamina_inc_max : 1000.0
# decriment threshold ,decriment step and minimum of player's recovery
# (default 0.3, 0.05, 0.1)
recover_dec_thr : 0.3
recover_dec : 0.002
recover_min : 0.5
# decriment threshold, decriment step, incriment threshold, incriment step
# and minimum of player's effort (default 0.4, 0.05, 0.9, 0.05, 0.1)
effort_dec_thr : 0.3
effort_dec : 0.005
effort_inc_thr : 0.6
effort_inc : 0.01
effort_min : 0.6
# maximum, recovery step and decay of player's hear capacity (default 2, 1, 1)
hear_max : 2
hear_inc : 1
hear_decay : 2
# inertia moment of player (default 5.0)
inertia_moment : 5.0
# interval of sense_body (default 100)
sense_body_step : 100
# goalie catchable area length, width (default 2.0, 1.0)
catchable_area_l : 2.0
catchable_area_w : 1.0
# goalie catchbale probability (default 1.0)
catch_probability : 1.0
# goalie catch ban cycle (default 5)
catch_ban_cycle : 5
# goalie max moves after catch (default 2)
goalie_max_moves : 2
# size, decay, random parameter, weight and maximum speed of a ball
# (default 0.15, 0.8, 0.2, 0.2, 32.0)
ball_size : 0.085
ball_decay : 0.94
ball_rand : 0.05
ball_weight : 0.2
ball_speed_max : 2.7
# force, direction and random parameter of wind (default 10.0, 0.0, 0.3)
wind_force : 0.0
wind_dir : 0.0
wind_rand : 0.0
# kickable margin (default 1.0) kickable_area = kickable_margin + bsize + psize
kickable_margin : 0.7
# corner kick margin (default 1.0)
ckick_margin : 1.0
# magnification of power in dash, kick (default 0.1, 0.1)
dash_power_rate : 0.006
kick_power_rate : 0.016
# angle of view corn [unit: degree] (default 90.0)
visible_angle : 90.0
# audio cut off distance (default 50.0)
audio_cut_dist : 50.0
# quantize step of distance for move_object, landmark (default 0.1, 0.01)
quantize_step : 0.1
quantize_step_l : 0.01
# max and min of power in dash and kick (default 100, -30)
maxpower : 100
minpower : -100
# max and min of power in turn (default 180, -180)
maxmoment : 180
minmoment : -180
# max and min of power in turn_neck (default 180,-180)
maxneckmoment : 180
minneckmoment : -180
# max and min of neck angle (default 90, -90)
maxneckang : 90
minneckang : -90
# Default port number (default 6000)
port : 6000
# Default coach port number (default 6001)
coach_port : 6001
# Default upper limit of the number of online coach's message (default 128)
say_coach_cnt_max : 128
# Default upper limit of length of online coach's message (default 128)
say_coach_msg_size : 128
# Default interval of online coach's look (default 100)
send_vi_step : 100
# time step of simulation [unit:msec] (default 100)
simulator_step : 100
# time step of visual information [unit:msec] (default 150)
send_step : 150
# time step of acception of command [unit: msec] (defalut 20)
recv_step : 10
# length of half of game [unit:sec] (default 6000)
# (if negative, a game does not stop automatically)
half_time : 300
# string size of say message [unit:byte] (default 256)
say_msg_size : 512
# flag for using off side rule. [on/off] (default on)
use_offside : on
# offside active area size (default 9.15)
offside_active_area_size : 5
# forbid kick off offside. [on/off] (default on)
forbid_kick_off_offside : on
# flag for verbose mode. [on/off] (default off)
verbose : off
# flag for record log. (default 2)
# (old version 1)
record_version : 2
# flag for record client command log. [on/off] (default off)
record_log : on
# flag for send client command log. [on/off] (default on)
send_log : on
# offside kick margin. (default 9.15)
offside_kick_margin : 9.15
#log_file: server.log
#record: record.log
#record_messages: on
#coach_w_referee
C Utdrag från Soccerserver Manual Ver 5 [4]
Agerande som agenten kan göra:

Indata från SoccerServern:

Initiering av agent:

I 8.6 skrev jag om testet mellan det självlärande och det enkla sparkbeteendet.
Här är statistiken som jag samlade på mig under de två försöken.
Försök 1:
| Match | Antalet mål för laget med självlärande beteende | Antalet mål för laget med enkelt beteende |
| 01 | 3 | 2 |
| 02 | 0 | 3 |
| 03 | 0 | 4 |
| 04 | 0 | 4 |
| 05 | 1 | 1 |
| 06 | 0 | 2 |
| 07 | 0 | 3 |
| 08 | 0 | 2 |
| 09 | 1 | 3 |
| 10 | 1 | 4 |
| 11 | 0 | 0 |
| 12 | 1 | 2 |
| 13 | 0 | 3 |
| 14 | 0 | 3 |
| 15 | 0 | 2 |
| 16 | 0 | 3 |
| 17 | 0 | 2 |
| 18 | 0 | 3 |
| 19 | 0 | 5 |
| 20 | 0 | 3 |
Extra statistik i försök 1 match 10:
| Spelare | Utförda bra sparkar | Utförda dåliga sparkar |
| 01 | 07 | 04 |
| 02 | 08 | 16 |
| 03 | 05 | 22 |
| 04 | 03 | 09 |
| 05 | 04 | 17 |
| 06 | 01 | 08 |
| 07 | 02 | 05 |
| 08 | 06 | 06 |
| 09 | 04 | 00 |
| 10 | 02 | 02 |
| 11 | 07 | 02 |
Försök 2:
| Match | Antalet mål för laget med självlärande beteende | Antalet mål för laget med enkelt beteende |
| 01 | 0 | 2 |
| 02 | 0 | 1 |
| 03 | 0 | 5 |
| 04 | 0 | 3 |
| 05 | 2 | 3 |
| 06 | 2 | 2 |
| 07 | 1 | 3 |
| 08 | 0 | 2 |
| 09 | 1 | 1 |
| 10 | 1 | 2 |
| 11 | 0 | 2 |
| 12 | 0 | 1 |
| 13 | 1 | 1 |
| 14 | 1 | 2 |
| 15 | 0 | 3 |
| 16 | 0 | 2 |
| 17 | 1 | 1 |
| 18 | 1 | 3 |
| 19 | 1 | 4 |
| 20 | 1 | 2 |
| 21 | 0 | 2 |
| 22 | 0 | 3 |
| 23 | 1 | 4 |
| 24 | 1 | 2 |
| 25 | 2 | 6 |
| 26 | 0 | 1 |
| 27 | 1 | 4 |
| 28 | 0 | 3 |
| 29 | 0 | 2 |
| 30 | 0 | 4 |
| 31 | 1 | 3 |
| 32 | 0 | 6 |
| 33 | 0 | 2 |
| 34 | 0 | 2 |
| 35 | 0 | 1 |
| 36 | 0 | 3 |
| 37 | 0 | 6 |
| 38 | 0 | 3 |
| 39 | 0 | 5 |
| 40 | 1 | 1 |
Extra statistik i försök 2 match 37:
| Spelare | Utförda bra sparkar | Utförda dåliga sparkar | Missade tidsdelar |
| 01 | 10 | 04 | 151 |
| 02 | 12 | 14 | 134 |
| 03 | 21 | 11 | 130 |
| 04 | 10 | 12 | 102 |
| 05 | 10 | 06 | 108 |
| 06 | 05 | 05 | 113 |
| 07 | 03 | 04 | 096 |
| 08 | 09 | 01 | 110 |
| 09 | 05 | 03 | 093 |
| 10 | 06 | 10 | 093 |
| 11 | 03 | 15 | 153 |
Extra statistik i försök 2 match 38:
| Spelare | Utförda bra sparkar | Utförda dåliga sparkar | Missade tidsdelar |
| 01 | 12 | 02 | 155 |
| 02 | 07 | 14 | 174 |
| 03 | 11 | 11 | 150 |
| 04 | 10 | 09 | 143 |
| 05 | 01 | 06 | 126 |
| 06 | 03 | 08 | 133 |
| 07 | 08 | 06 | 129 |
| 08 | 06 | 03 | 124 |
| 09 | 06 | 02 | 153 |
| 10 | 10 | 03 | 131 |
| 11 | 15 | 10 | 120 |
Extra statistik i försök 2 match 39:
| Spelare | Utförda bra sparkar | Utförda dåliga sparkar | Missade tidsdelar |
| 01 | 10 | 07 | 37 |
| 02 | 02 | 09 | 34 |
| 03 | 11 | 25 | 37 |
| 04 | 03 | 09 | 33 |
| 05 | 06 | 07 | 36 |
| 06 | 05 | 10 | 40 |
| 07 | 02 | 04 | 44 |
| 08 | 09 | 04 | 42 |
| 09 | 03 | 02 | 33 |
| 10 | 06 | 03 | 37 |
| 11 | 12 | 08 | 37 |
Extra statistik i försök 2 match 40:
| Spelare | Utförda bra sparkar | Utförda dåliga sparkar | Missade tidsdelar |
| 01 | 08 | 05 | 21 |
| 02 | 07 | 06 | 18 |
| 03 | 09 | 16 | 15 |
| 04 | 03 | 06 | 25 |
| 05 | 06 | 12 | 20 |
| 06 | 05 | 05 | 17 |
| 07 | 03 | 09 | 20 |
| 08 | 08 | 04 | 15 |
| 09 | 04 | 03 | 25 |
| 10 | 04 | 09 | 22 |
| 11 | 06 | 06 | 25 |